
Filter Out Inaccurate Media Data for Better ASR
Video Subtitles are Worthy Training Data
Modern media platforms provide a vast amount of video content to appeal to diverse audiences. Popular categories include movies, TV series, OTT (over-the-top) services, and live streams. These often feature human speech, which can create a language barrier for people who speak different languages.
To attract global viewers, video providers offer subtitles in one or more languages. These subtitles often include the spoken language itself to support people with hearing difficulties (such as those with hearing impairments or people in public places without earphones) and sometimes to enhance the viewing experience with relevant information.
Subtitles not only help people enjoy videos but also serve as valuable training data for AI models. Specifically, pairs of audio streams and subtitles in the same language can be used to train automatic speech recognition (ASR) models.
Automatic Speech Recognition (ASR)
ASR involves predicting a transcript from a segment of speech input, providing useful functions for media content, such as automatically generating captions for videos. State-of-the-art ASR models [1-3], which utilize deep learning techniques, require paired speech data and transcriptions for training. Achieving high accuracy with deep learning ASR models follows a strong principle: the more high-quality training data available, the better the ASR performance [4, 5].
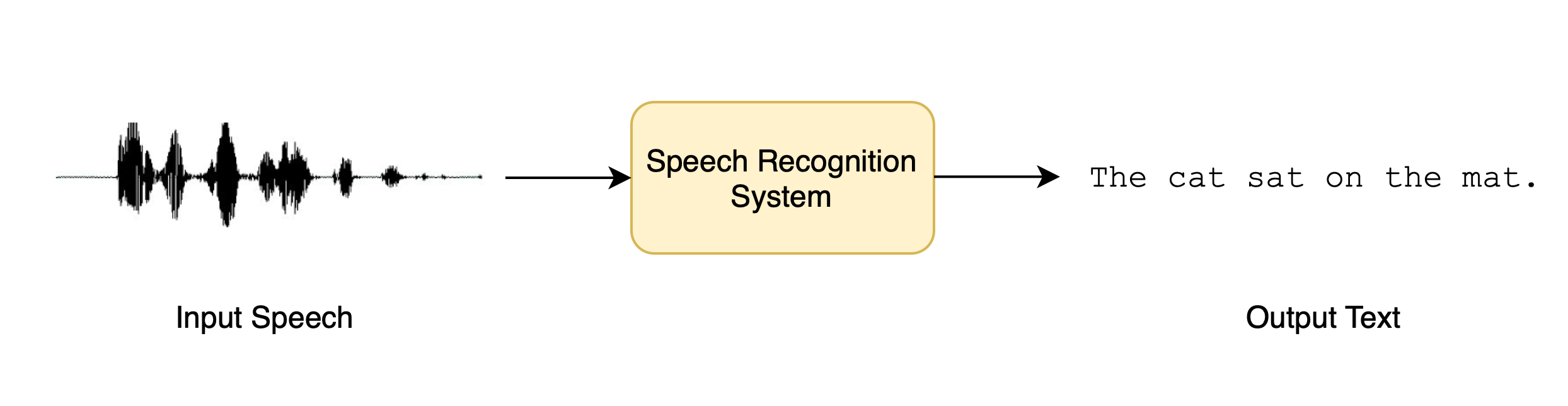
Thanks to the rapid development of the media ecosystem, collecting transcribed speech data is relatively easier than ever, although it requires appropriate data licenses for building a commercial ASR system. Accessing a substantial volume of training data can be achieved by carefully crawling open-source data, investing in purchasing data from third-party companies, or making contracts with customer companies for the use of in-house data.
Training with Inaccurate Transcripts Degrades ASR Accuracy
All the data collection methods mentioned earlier share a common problem: partially inaccurate transcripts. In other words, some portion of speech data may be paired with transcripts that do not match what is actually spoken. Even datasets that are quality-controlled by humans contain a non-negligible number of errors, which can degrade the accuracy of the trained ASR model. Thus, to achieve the best ASR performance, the inaccurate transcript problem should be addressed explicitly. One impressive approach is to employ a training method that is robust to missing transcripts [6], but it is not applicable to all types of transcription errors. A general solution would be to filter out all suspicious transcripts from the dataset.
Especially when transcripts are extracted from video subtitles, which is the most common scenario for media ASR data collection, even error-free subtitles can serve as ‘inaccurate transcripts’ for several reasons. The first reason is unspoken subtitles. Subtitles are not guaranteed to present the actual spoken words. Subtitles often contain on-screen messages that may describe video production information (e.g., “This video is financed by …”), emphasize visual signs on the screen (e.g., “Yield sign”, “Hogwarts castle”), or intentionally make puns to entertain viewers. Human labelers sometimes reinterpret or ignore some speech segments to provide the most compact and comprehensible subtitles to viewers. For example, a labeler might write a subtitle for a speech segment like “No no no no… I can do it” as “No X 4 I can do it” or simply “I can do it”.

The second reason is inaccurate timecodes. The start and end timecodes of a subtitle do not always match the actual speaking timing. Subtitle timecodes are set so that viewers can easily read the subtitles while watching the video. Some subtitles appear much earlier than the actual beginning of the speech, and a subtitle may disappear in the middle of speaking to display another subtitle for the subsequent utterance.
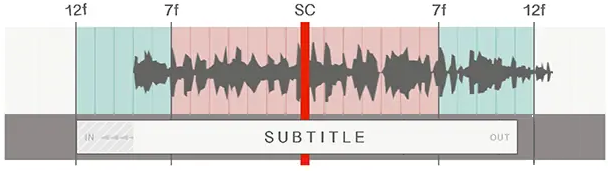
Filtering Out Inaccurate Subtitles
Although it is crucial to eliminate the inaccurate subtitles to train an accurate ASR model, determining the correctness of a subtitle is not a trivial task. The determination can be approached in two ways: rule-based filtering and ASR-based filtering.
Hard-coded rules can remove a modest substantial portion of inaccurate subtitles. Ideally, human labelers are instructed to tag unspoken subtitles with special markers (e.g., on-screen messages are wrapped in brackets). In this case, a simple strategy of removing every text tagged with the markers will eliminate almost all unspoken subtitles. However, realistic subtitles are not perfectly normalized due to naive data labeling schemes and individual labeler mistakes. Hard-coded rules may fail to filter out some unspoken subtitles. Moreover, rule-based filtering can only detect unspoken subtitles, not the inaccurate timecodes.
A complementary solution involves utilizing a pretrained ASR model to detect inaccurate subtitles. Modern ASR models [1-3] have ability to estimate the probability of a text given the speech segment. A heuristic decision policy built upon ASR probabilities can filter out remaining incorrect subtitles after rule-based filtering. This approach can determine if an audio-subtitle pair is suspicious, regardless of whether the issues are due to unspoken subtitles or inaccurate timecodes. An innate disadvantage of the ASR-based filtering is that it also removes some accurate subtitles, which can be mitigated by enhancing the accuracy of the ASR model. One solution is the iterative ASR-based filtering scheme. In this scheme, the training set reduced by applying ASR-based filtering is used to train a new ASR model, which is then employed as the model for the next iteration of ASR-based filtering, and so on. The iterative ASR-based filtering allows us to keep more portions of accurate subtitles, therefore enhancing the accuracy of the trained ASR model.
At XL8, we apply both filtering approaches to clean up to ASR training data. Our empirical evaluations showed that the filtering removes a significant proportion of inaccurate subtitles, which resulted in improved accuracy of the trained ASR modeled in enhanced performance of the trained ASR model.
‣References
[1] A. Graves et al., "Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks," Proceedings of the 23rd international conference on Machine learning, 2006.
[2] A. Graves, "Sequence transduction with recurrent neural networks," presented at ICML 2012 Workshop on Representation Learning, 2012.
[3] W. Chan et al., “Listen, attend and spell: A neural network for large vocabulary continuous speech recognition,” in Proc. ICASSP, 2016, pp. 4960-4964.
[4] W. Chan et al., “SpeechStew: Simply mix all available speech recognition data to train one large neural network,” arXiv preprint arXiv: 2104.02133, 2021.
[5] A. Radford et al., “Robust speech recognition via large-scale weak supervision,” in Proc. ICML, 2023, pp. 28492-28518.
[6] V. Pratap et al., “Star temporal classification: Sequence classification with partially labeled data,” arXiv preprint arXiv:2201.12208, 2022.
Contributors
Sean Lee
Research Scientist


