Glossary Usage for best translation quality
XL8’s is an AI-powered Machine Translation (MT) company with engines that have scored over 95% accuracy in select language pairs, and its MediaCAT platform is offering a media-based workflow that customers find reduces their translation time and cost by up to 40%.
We offer two product lines: MediaCAT and EventCAT. MediaCAT covers our file-based or VOD workflow with speech to text, translation and synthetic voice. EventCAT covers the same basic areas but in a live setting. This glossary discussion is covering the functionality of the MediaCAT platform as EventCAT glossaries are slated for early 2023.
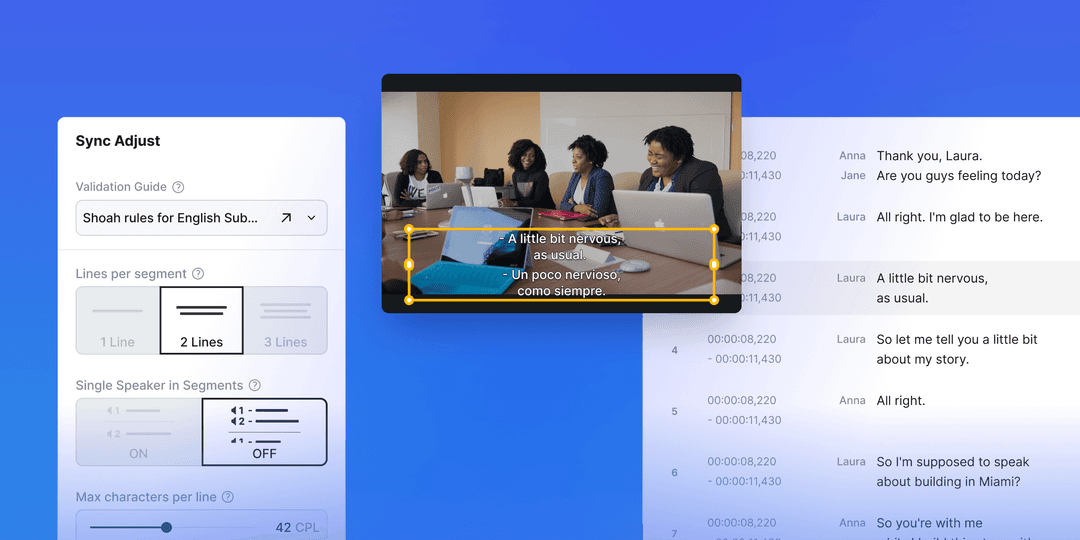
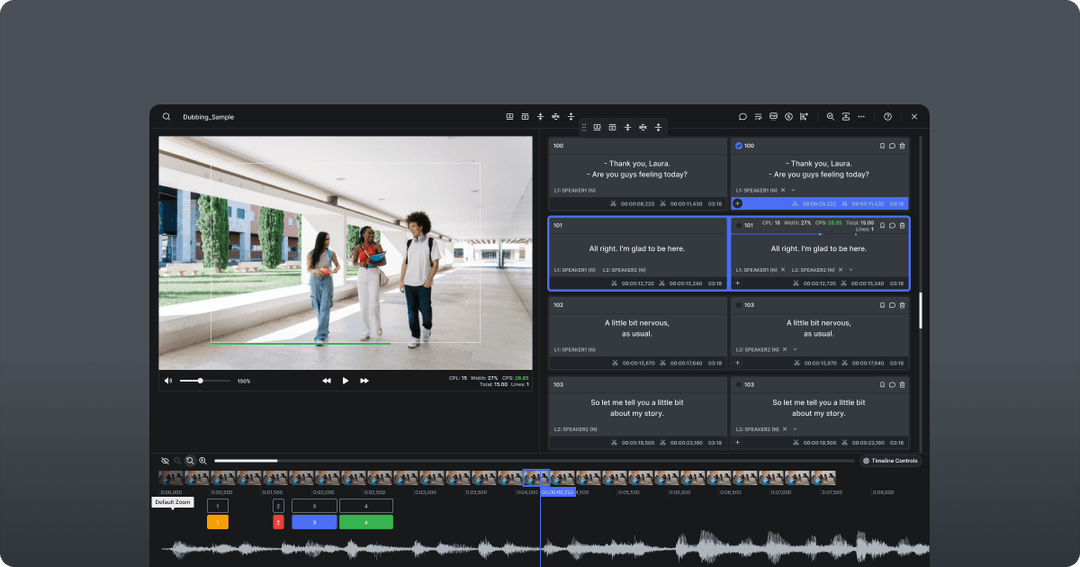
Sync is a powerful tool that allows users to perform speech to text transcription and synchronization between text and media files. This means that the software is able to convert spoken words into written text, and it can also align the text with the corresponding audio or video file. This is incredibly useful for a variety of purposes, such as creating subtitles for videos, transcribing interviews or meetings, or creating a dialog list for dubbing. The ability to sync transcription files with media files also makes it possible to quickly and easily create an accurate timed file regardless of formatting changes or frame rates. Overall, Sync is a versatile and powerful tool that can greatly improve productivity and efficiency in many different contexts.
AI software called Translate uses natural language processing (NLP) techniques to analyze and understand the source language text and then generate translations in many target languages simultaneously. The software has been trained on a large dataset of translated text and uses this knowledge to generate accurate and fluent translations. The generated translation is then used to create subtitle files in the target language, which can be displayed on a video player to provide subtitles for viewers who don't speak the source language. This allows for greater accessibility and understanding of the video's content for a wider audience.
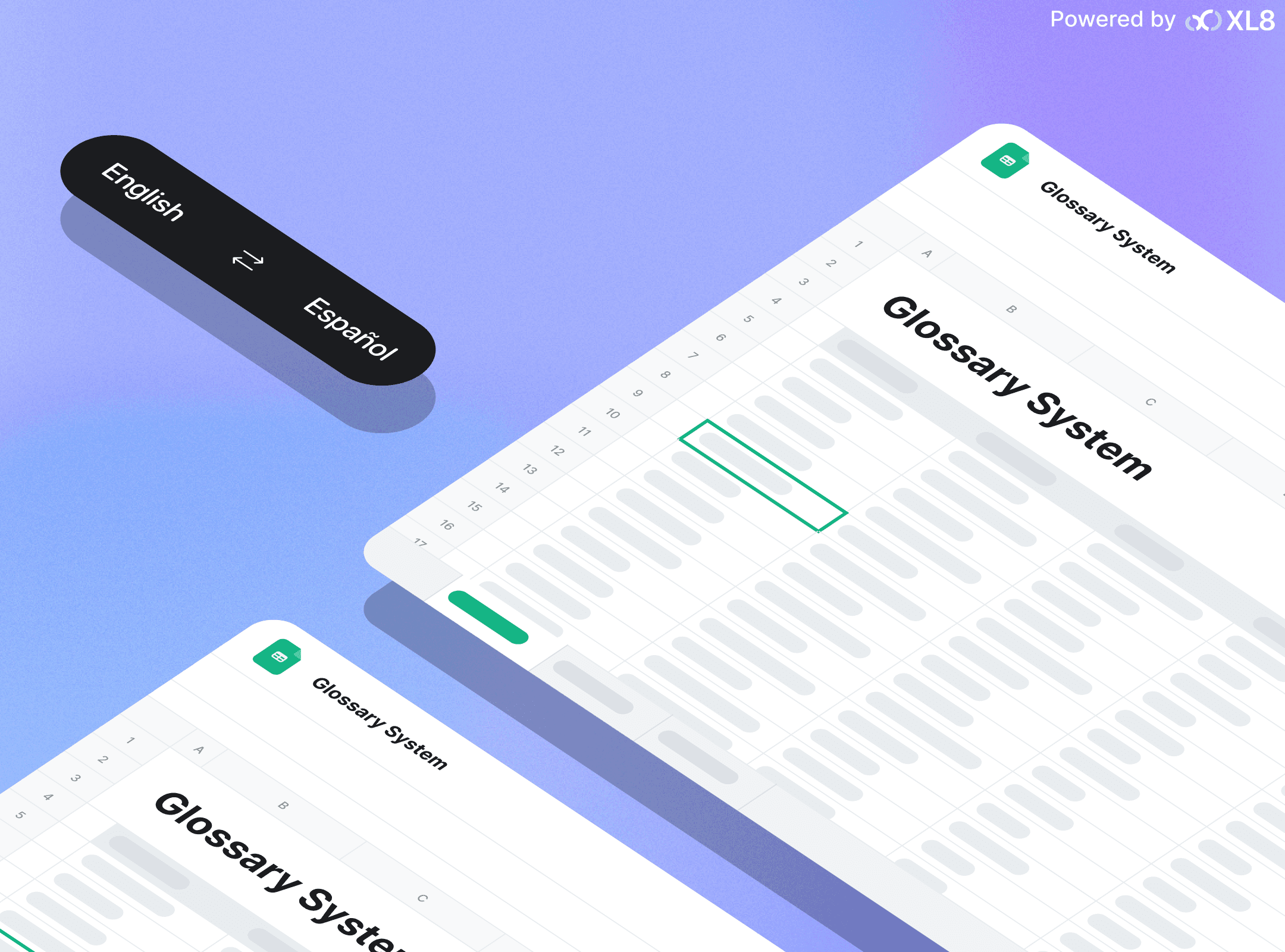
Although our media and entertainment specific engines are uniquely trained and regularly updated, there are still words that could cause issues, either through unique spelling or an unusual interpretation. That’s where the glossary function comes in. We allow our customers to create .csv files containing words that might be unique, like names, or unusual spellings like Forrester instead of Forester.
We enable glossaries in two places. First, through Sync as a tool to aid in capturing spelling accuracy and word identification for speech to text jobs. Glossaries provide better accuracy for sporting events or scripted content where accurate spelling and use of proper nomenclature is paramount to a successful viewing experience.
For example, Martin Ødegaard is a Norwegian professional footballer who plays as an attacking midfielder for Premier League club Arsenal. Without the glossary, the engine detects the following line:
SPEAKER 3: Would have gone hurriedly on with it.
This doesn’t capture Martin’s name correctly, and Arsenal fans wouldn’t be too happy. However, using the one-column CSV file with the player roster helps Sync capture it correctly:

Now, when I reprocess the file with a glossary, we get the correct result.

Along with any required post-edits, that can be easily accomplished with our subtitle editor. we can create an accurate transcription of the source language that is ready for translation. This example is for an English source, but it works the same for the many different languages that we have enabled in Sync.
You can imagine that you could have different sets of glossaries available to use simultaneously, like by series, or genre, or by specific slang terms. There are as many ways to use the glossary function as you can imagine. Remember, the more accurate the source translation is, the better the subsequent machine translation will be.
Glossaries are especially helpful in Translate, and we use a three-column csv file with source, target and case sensitivity to capture the original language source and the preferred translated word. Offering multiple source and target pairings for each language translation allows us to capture specific words by genre, domain or by a specific title. I find it very valuable for a long running series with many recurring locations and character names. You can create source and target pairs for each language you want to translate.
Here is an example from a Turkish drama. The character name is Yılmaz, which translates in English to “Unyielding.”
The line from the drama is:
Yılmaz geç kalıcaz.
A straight translation into English gives:
We'll be tardy.
Once I make a Glossary with character names,
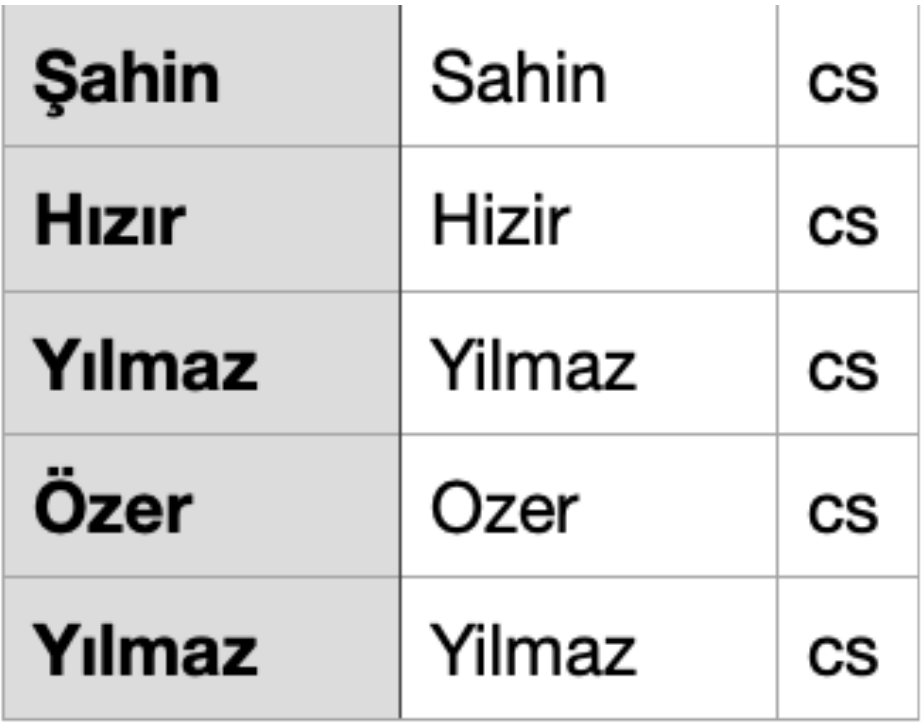
we get the correct result:
Yilmaz, we're going to be late.
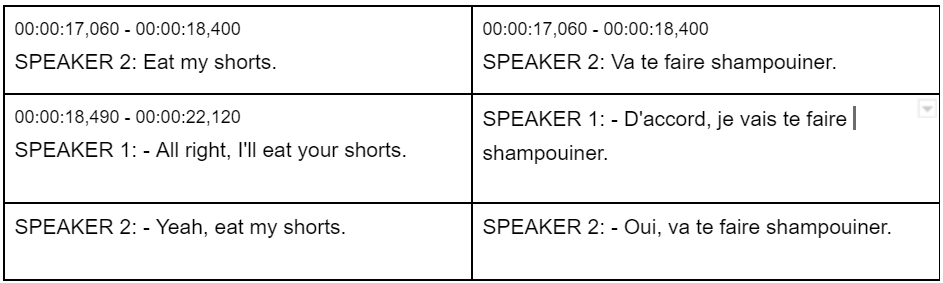
There are catch phrases in many shows that need to be translated correctly. Imagine if you were working on a show like THE SIMPSONS, and Bart has a catch phrase, “Eat my shorts.” The official French version is supposed to be, “va te faire shampouiner” but the literal translation is, “Bouffe mon short.”
If we add this phrase and set it to case insensitive,

It will catch this catch phrase every time.
It will catch this catch phrase every time.
Another example of how glossaries can help is in the area of what I call “Profanity Modification.”
I have a phrase in Latin American Spanish that is ¿Qué carajo? It is not appropriate for all audiences and the customer wanted to replace the English translation to “What the heck?”
Instead of searching scripts for offending words, you can simply create a glossary that changes the translation of “carajo” to “heck”. In this case I chose it to be case sensitive because it was never used as a capitalized term.

This works across different languages and the easy upload allows you to have multiple glossaries in play when needed.
You can imagine the possibilities of creating lists of words or short phrases that slightly change translations to suit new markets. We allow for multiple glossaries to be implemented simultaneously, so a cast list, catch phrase list and specific translation lists are all available for any project.
The nice thing about our glossary is that it isn’t a bolted-down, one-to-one matchup. It takes the probability of the words into account. When I use a glossary that directs a translation to a word that has a specific meaning, the system will look at the probability that the word is being used in that context before replacing it. This helps drive accuracy for the whole document, not just that single word pair.
That’s how we do these file-based translations, as an entire document. We take it all into account as we run a translation job. We are not just translating a single word at a time, or even a single sentence at a time. Our context aware pairs look at the content before and after the sentences we translate, for greater accuracy. We’re able to capture the context of the conversation and determine if the word for “sheet” is in relation to “changing the bed” or “changing the tray in a copier.” Whether you choose to post-edit or not, using a glossary is another tool to save time and money by leveraging the power of AI to get the closest possible accuracy.
Written by John Butterworth, Vice President Sales Engineering
Contributors
John Butterworth
SVP, Customer Success and Operations