How to Improve the Accuracy of Machine Translation: Age-Gender Prediction in Media
Why do we need age-gender prediction?
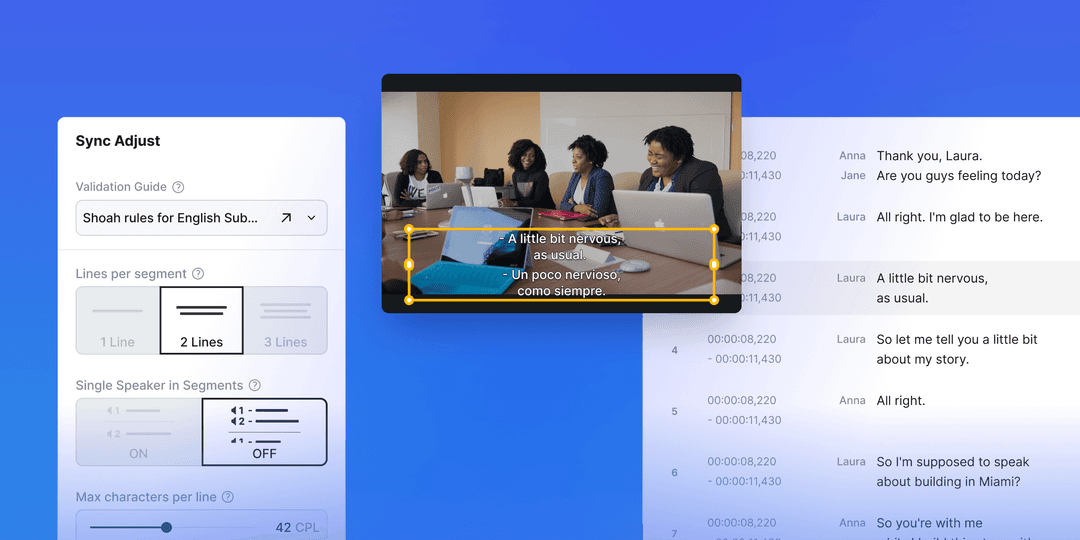
Age-gender prediction is meta information that could be used in translation. This enriches the quality of the result of translation. Languages are complex in that words are used differently along the speaker’s ages and genders. There are languages where words change slightly based on the speaker’s gender and a difference in frequency in how many they are spoken by a female compared to a male. Age is also important in translation. You probably know teenagers that seem to use their own language. Teenager’s words are different from their parents. When we ignore these differences, the translation result will sound unnatural when the native speakers listen to them.

The third concern is formality. Some languages pick different words based on the person they are speaking to. Without the correct formality, it will sound very rude. The reason why machine translation has not been fully adopted is that for the past several years, it has literally sounded like a machine but not a person. What if we could tell the age and gender of the speakers and utilize them in translation? The machine would speak more like us. Today, we call this multi-modal AI.
How we get predictions in media
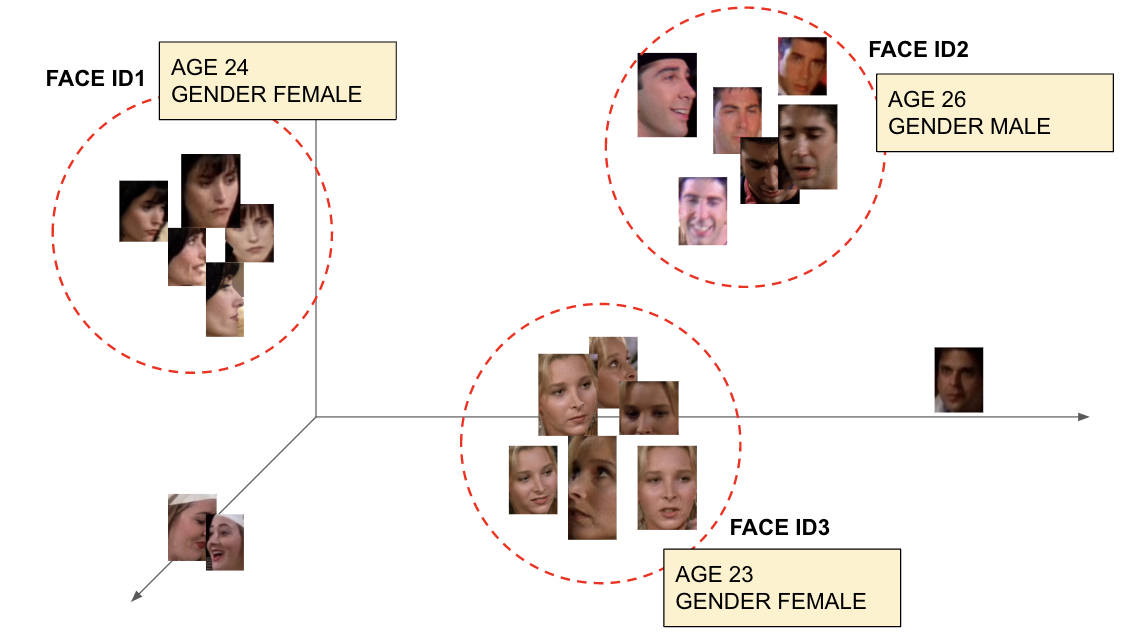
Thanks to massive research over the past few years, Age-gender prediction has become easier. The real problem is around speaker diarization which solves the problem of “who spoke when.” Why do we care about age-gender prediction? Because we don’t predict age-gender in each scene. Instead, we collect all the faces from the video at once, cluster them according to their resemblance and assign them face IDs.
The Challenge of Accurate Speaker Diarization in STT!
Although many STT services provide speaker diarization functionality, the quality seems to be under the point to be useful in real scenarios. Usually the number of speakers produced is less than the actual amount. This means two different people could be identified as identical. This is the critical problem for age-gender prediction. It absolutely needs to identify people correctly.

A Two-Pronged Strategy for Accurate Speaker Diarization
By extracting face images and clustering them, we have learned that speaker diarization by face derives better results than those that come from STT. There is research that proves recognizing a person by face is more accurate than with voice. Even though the research comes from the field of human perception not from artificial intelligence, we believe this is relevant to the field of AI as AI simulates human’s behavior. (Ref. https://www.psychologicabelgica.com/articles/10.5334/pb.ap/)
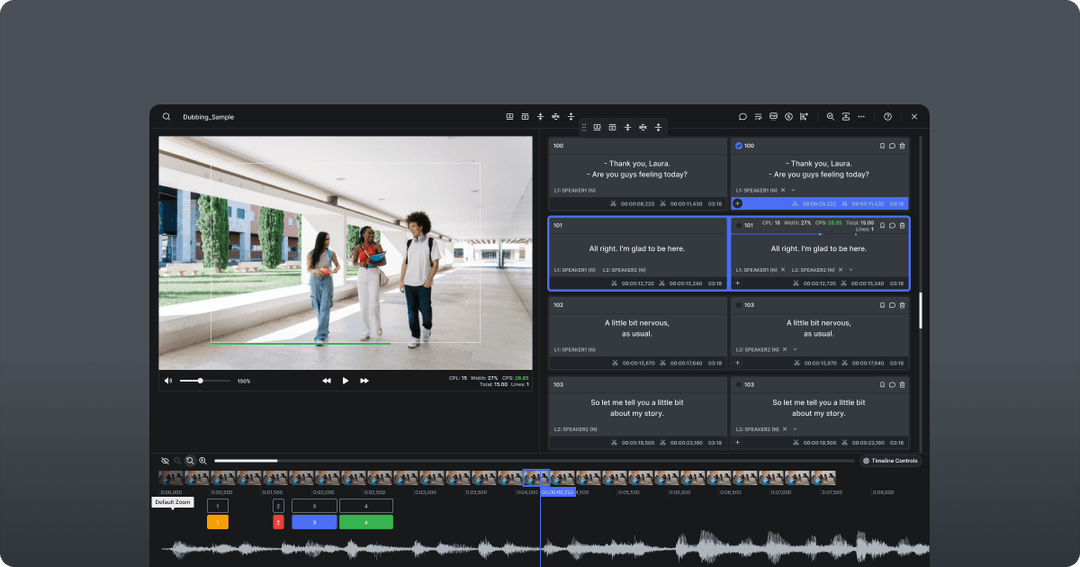
Our strategy is simple. Use face-based speaker diarization first and get support from STT-based speaker diarization when it fails to infer the speaker at a certain moment. To implement face-based speaker diarization, we employed our speaker-detection-net which detects if the person in the scene speaks or not and who is speaking in case that there are multiple speakers in the scene. Because it’s not always that the person in the frame is the current speaker, we need to verify if this person is really the one who is speaking. This is done by the speaker-detection-net, which is an RNN based net taking the variation of the distance of lips in time-series.
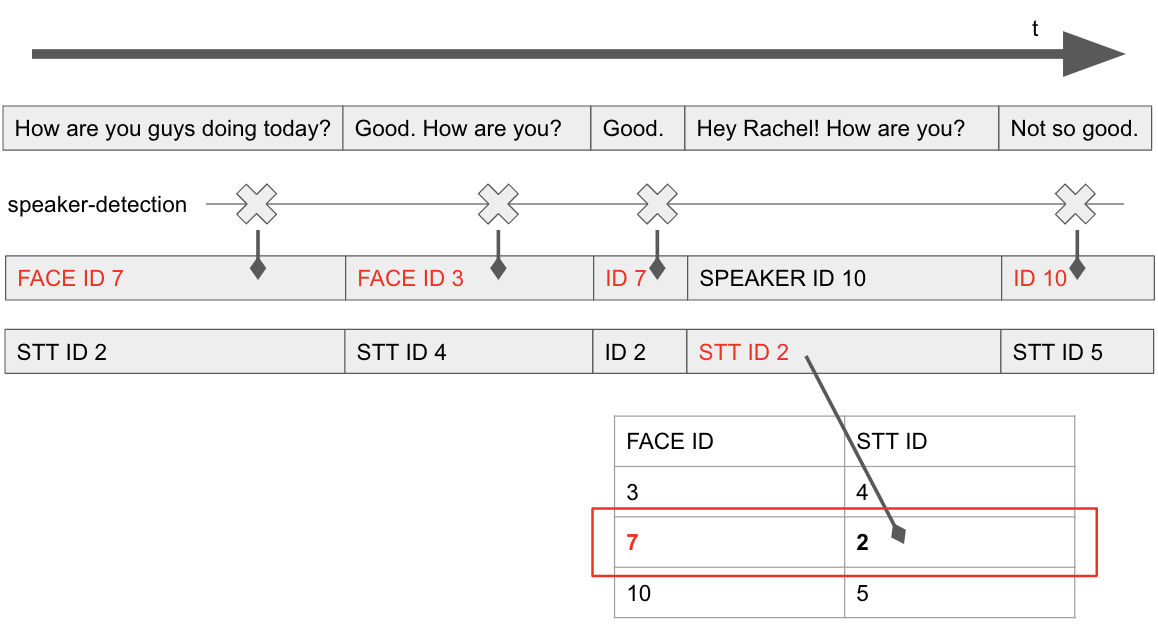
For each line, we check if there was any detection. If so, the speaker is the one who speaks the line. If there was no detection, we have to infer through the result of speaker diarization STT conducted. Imagine a scene where a person who is spoken to is close to the camera. There must be no speaker detection occurring in the scene. Then, we match the face-based speaker IDs with the STT-based speaker IDs along the co-occurrences between them. Since there’s no detection, we see the STT-based speaker ID, follow the mapping between them and pick the face-based speaker ID. No wonder we humans already do this when we don’t see the person’s face but just listen to their voice.
Taking Speaker Diarization to the Next Level with Multi-Modal Clustering
Multi-modal clustering would be the next step for improving this. We humans don’t recognize persons by seeing only their faces with our ears closed or listening only their voice with our eyes closed. We take all of the information in at the same time. To simulate this, we cluster people with representations consisting of voice and face characteristics. This will increase the performance of the model and reduce the error that happens when we use only one modal.
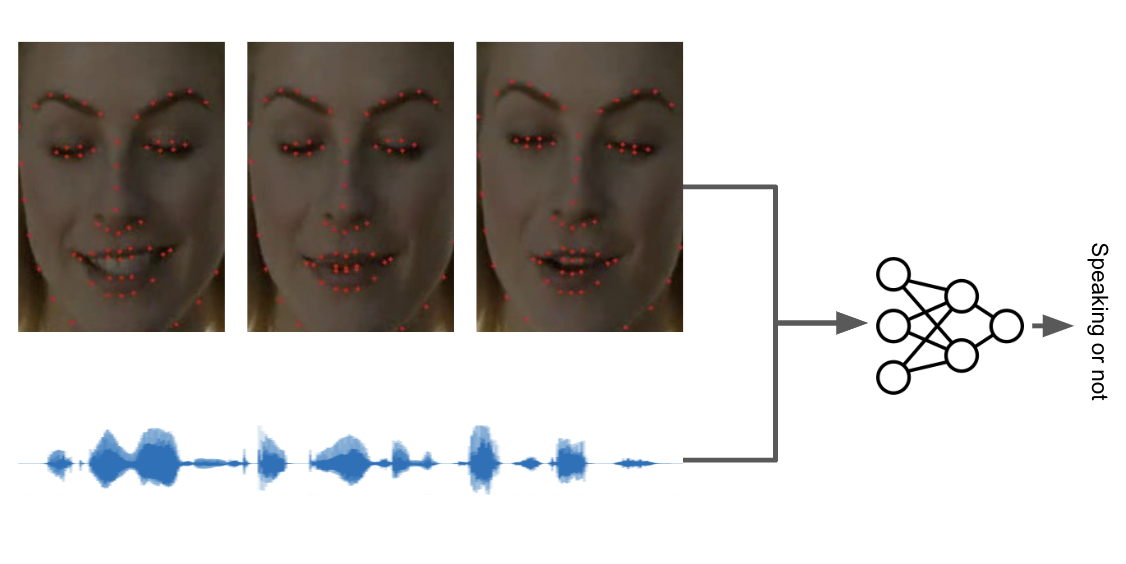
Second thing we do to improve this is the speaker-detection taking not only the distance of lips but also the amplitude of voice that comes at the moment. Detecting whether speaking or not is tricky as we humans also will have trouble without sensory organs. Introducing multimodal speaker-detection, we complete more reliable detection.
Conclusion
Multi-modal AI is not a new concept but we didn’t have the proper methods and tools to utilize them. Thanks to the steep enhancement of AI technologies, we have just started to be able to utilize that information. We believe this is a positive feedback loop and this expansion will make the thing that wasn’t possible to achieve yesterday, possible today.
Written by Leo Younghyo Kim, Backend Engineer
Edited by Ted Bae, Frontend Lead
Contributors
Leo Kim
Backend Engineer