
Machine Translation Evaluation: How XL8 Gets It Right
Introduction
XL8 offers a Machine Translation (MT) service, uniquely optimized for media and entertainment content. As an MT provider, accurately evaluating the performance of our MT systems is crucial to us. However, whether translation was done by a human or a machine, evaluating the translation results is challenging. There often can be more than one way to correctly translate a sentence and, in most cases, not all of them are accessible during evaluation. Even for the same source sentence, different evaluators may choose different translated sentences as the most accurate translation, based on the context or due to the personal preference of each evaluator. Another challenge in evaluating translation are the different dimensions of translation quality. Should we prefer adequacy over fluency or the opposite? What if one translation is fluent but slightly inaccurate, compared to another that is accurate but unnatural? How can we quantify the quality of translation over these different dimensions?
There is no simple answer to these questions. In fact, along with improving the quality of MT, automatically evaluating its results both efficiently and reliably is one of the most important and yet difficult research topics in the MT community. A significant amount of effort has been devoted to developing an automatic MT evaluation method that can be as reliable as human judgment. Although MT evaluation has continuously evolved, at the time of writing, it is still an open problem and no perfect solution exists. Because of this, MT researchers and developers need to resort to imperfect evaluation methods which often lead to suboptimal or sometimes even erroneous conclusions.
In this blog post, we will introduce various categories of MT evaluation and review the most popular metrics in each category and the pros and cons of each. We will also cover the way XL8 is evaluating MT engines in our MT development cycle and how it is distinguishable from other approaches.
Manual evaluation (human judgment)
Without a doubt, the most reliable and precise evaluation of MT systems is human judgment. As we will see later in this blog, most automatic MT evaluation metrics aim at scoring MT systems as close as humans do. Depending on the objective of evaluation and available resources, several frameworks for human evaluation of MT systems have been proposed. Here we briefly review a few of the most well-known ones.
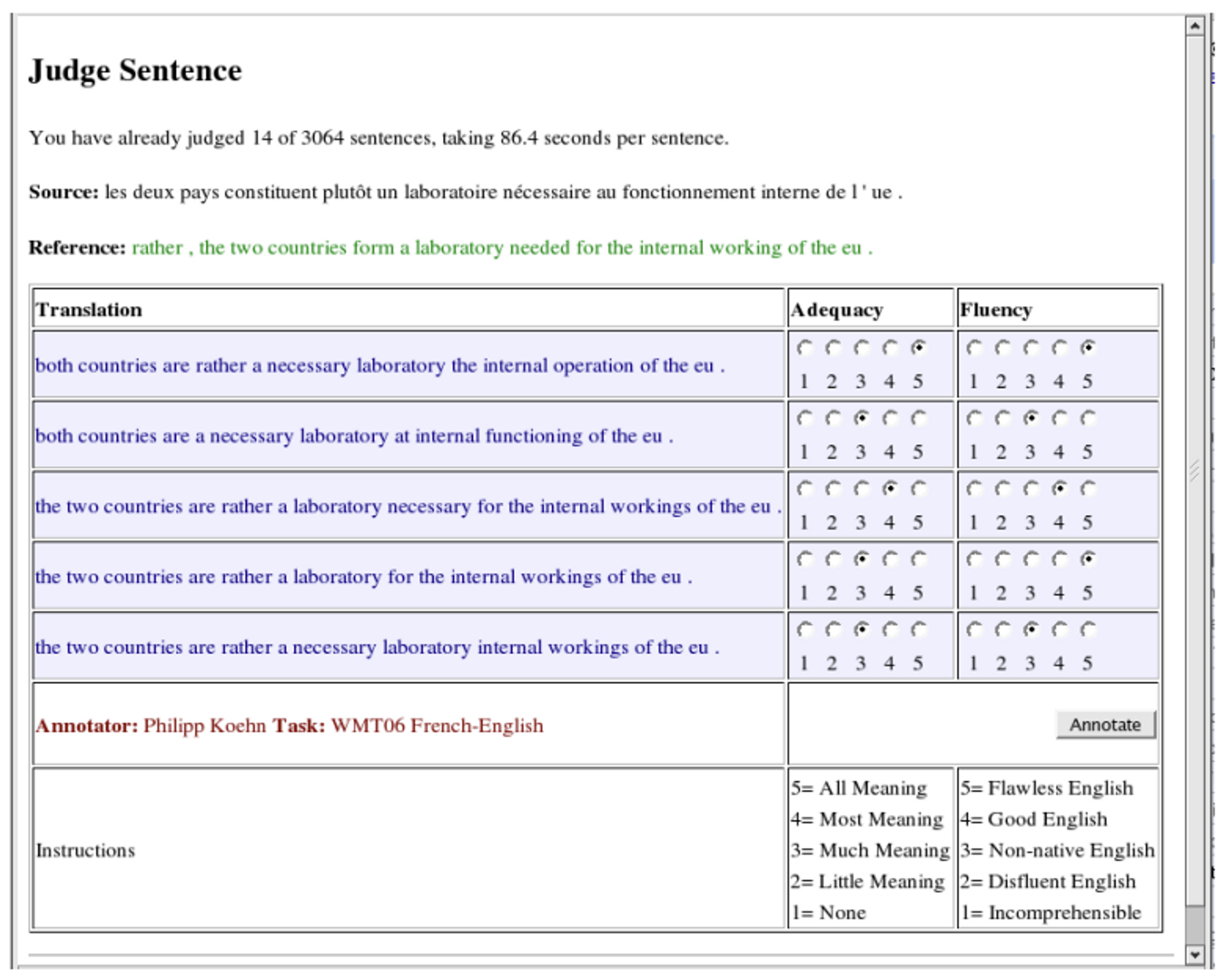
1. Scoring adequacy and fluency [1]
To rank the translation quality of different MT systems, this task requested evaluators to assign adequacy and fluency scores on a scale of 1 to 5. Since the goal of this evaluation was to rank different MT systems by conducting the pairwise comparison of one another, it was not designed to measure an absolute score of translation quality. Because of this, the evaluation criteria of adequacy and fluency was not precisely defined, and evaluators were forced to discretize their assessments into a fixed number of categories. This caused the scores from the evaluators to be arbitrary and inconsistent. This scale was used for the first evaluation of machine translation on WMT (Conference on Machine Translation) [2].
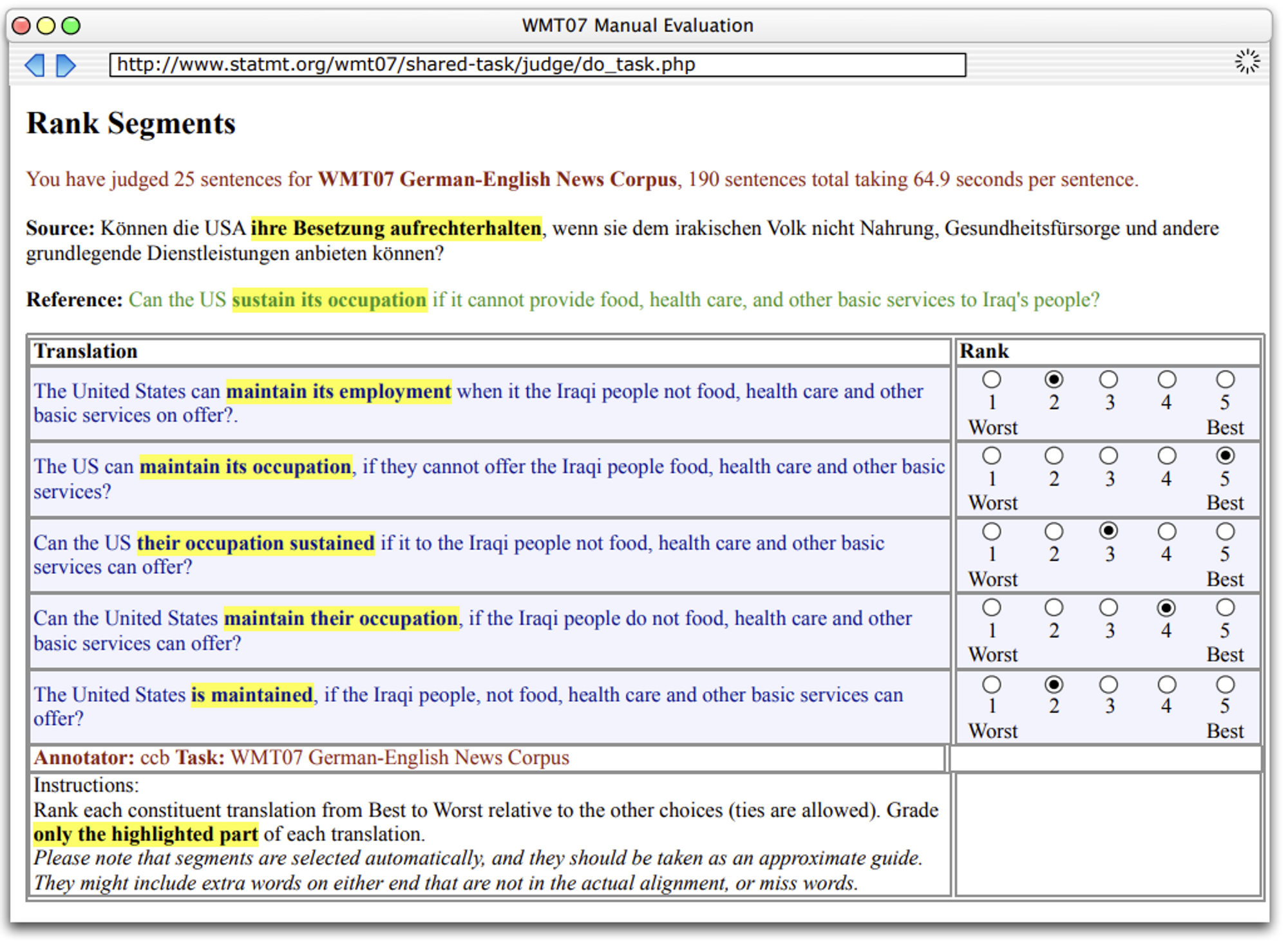
2. Ranking [3]
From WMT 2007, ranking translations of sentences and syntactic constituents was proposed. The motivation was that fluency and adequacy were difficult to measure and it was difficult to maintain consistent standards on each of the five scales. To make evaluation easier, the instructions were changed to compare different translations of a single sentence and rank them, from worst to best. This ranking-based evaluation had been used as the official metric of WMT until 2016 [4].
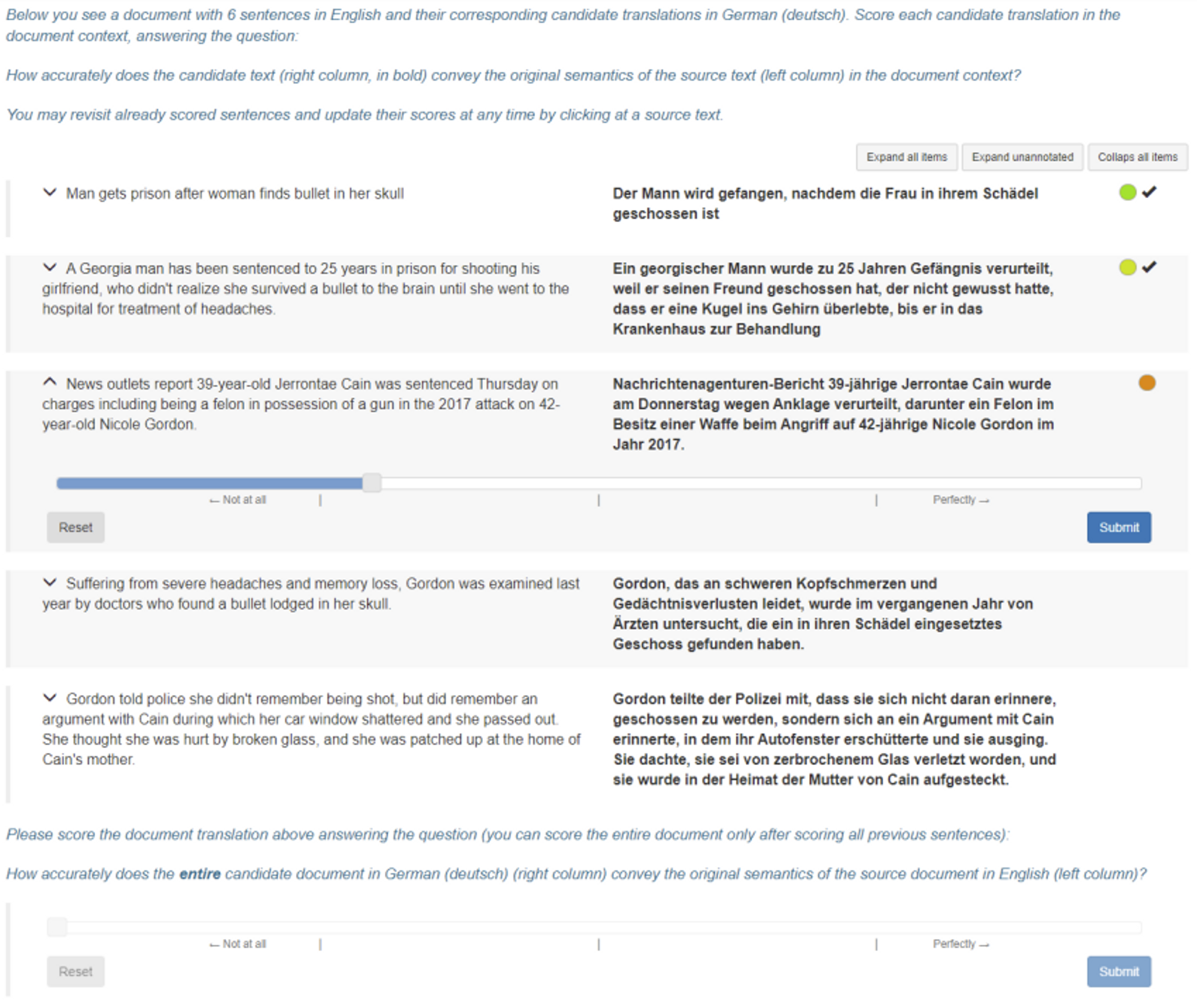
3. Direct Assessment (DA) [5]
To overcome the inconsistency problem of the five scale evaluation, DA was proposed. It requires evaluators to score a translation quality on a continuous rating scale of 0 to 100. DA was expected to be more suitable to MT evaluation because the continuous rating more fits to the continuous nature of translation quality assessment, and normalizing scores (or applying other statistical methods) is easier for continuous data than interval-level data.
Another benefit of DA is that it doesn't require pairwise comparison of MT systems, which became problematic when the number of MT systems rapidly increased with the advancement of Neural Machine Translation (NMT). DA focusing on adequacy has been the official WMT metric since 2017 [6].
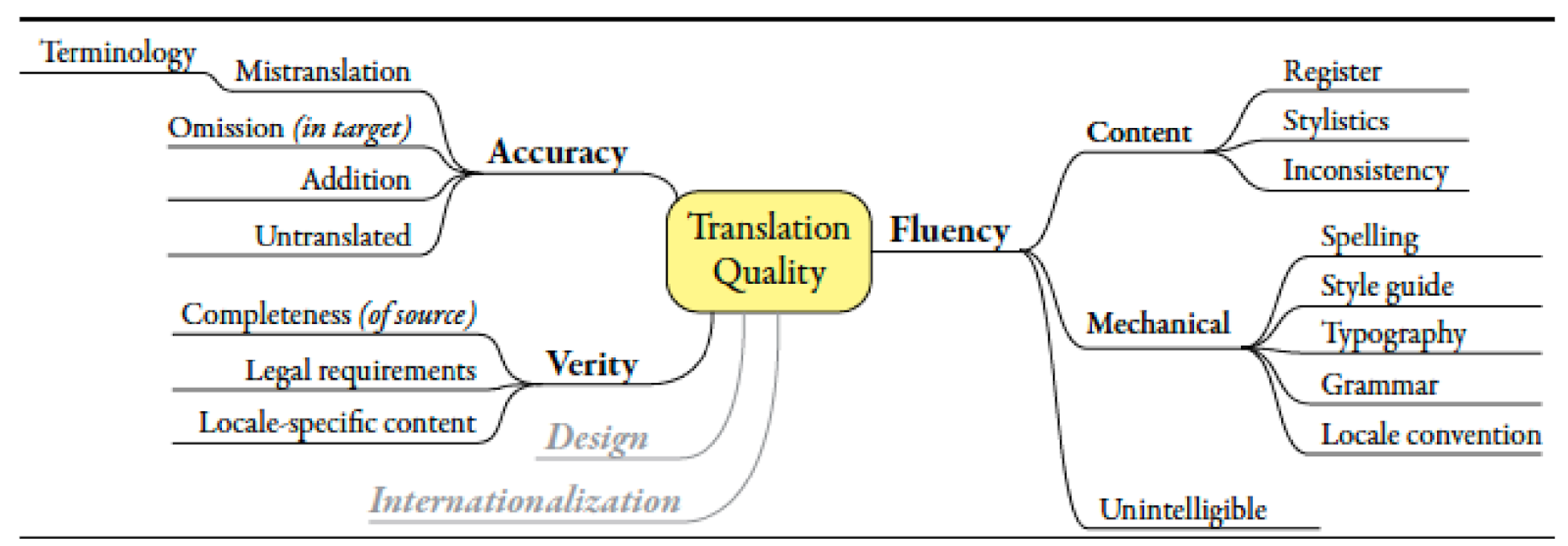
4. Multidimensional Quality Metrics (MQM) [8]
MQM was originally rooted in the need for quality assurance for professional translators, and was proposed as an alternative to the aforementioned metrics. It aims at providing a translation quality metric that allows a fine-grained analysis of translation quality, while at the same time being flexible to be adapted to various evaluation needs. MQM defines a hierarchy of error categories, and evaluators are required to assess fine-grained error categories like omission, register and grammar. MQM can also be adapted to assign a single score for each translation segment, by defining severities of errors (e.g. Major, Minor, Neutral) and weighting errors according to them [10].
MQM is known to be very effective in assessing translation quality and widely adopted for quality assurance in the translation industry. However, MQM has been rarely selected as a metric for MT evaluation, because the fine-grained analysis and annotation of errors make it significantly slower and more expensive to perform.
We would like to note that human evaluation can also be imperfect and noisy. It has been found that evaluation results from non-professional translators are often less accurate than results from advanced automatic evaluation metrics [10]. In WMT evaluation campaigns, a quality control was needed to filter low quality evaluations from crowd workers [7]. Nonetheless, properly designed human evaluation conducted by experts undoubtedly is the most reliable way of evaluating MT systems, and research efforts on improving human evaluation frameworks are still actively being underway. These include developing an explainable evaluation metric [11], improving evaluation efficiency [12] and taking uncertainty into account [13]. With these great ideas and efforts, we are pretty sure that the quality of MT evaluations will continuously improve, and it will further help advance MT quality in the future.
Automatic evaluation
Evaluating outputs of MT engines is a daily job for an MT developer. During the training process, the output of the engine is evaluated frequently. After finishing training, the output of the engine is evaluated on a testing dataset to compare its performance with previous engines or competitors. After an engine is deployed, its output needs to be periodically evaluated to make sure it is still working fine with recent data distributions. Although manual evaluation methods discussed in the previous section are the most accurate way of doing so, it is infeasible to use them because 1. they are prohibitively expensive to do many times and 2. they are often too slow to provide rapid feedback and fast decisions. A viable alternative is automatic evaluation metrics designed to measure MT qualities. Automatic MT evaluation is an important research area that has received significant attention from the community, and meaningful progression has been achieved in recent years. Here we segment automatic MT evaluation methods into two categories and introduce a few of the most representative metrics in each category.
String matching-based metrics
The most common process of automatically evaluating MT quality is to compare MT outputs with human reference translations in a string (a sequence of words or characters) level. They are also called non-meaning based metrics as they compare two segments of text on their surface form, rather than considering the actual meaning.
1. BLEU (bilingual evaluation understudy) [14]
BLEU is the most widely used and well-known metric in this category. The exact formula might look quite complicated at the first glance, but the main idea is simple: use a weighted average of variable length phrase (n-gram) matches against the reference translations.
‣ For those who are curious, here is a brief overview of how it works :
Firstly, it counts how many n-grams in the MT output overlap with one of the references. Then it sums the number of matches for the entire document, and divides it by the number of entire n-grams in the document. It calculates this “modified n-gram precision” from 1-grams (unigrams) to N-grams (most commonly 4-grams) and combines them as a single score using weighted geometric mean. Finally, it is multiplied by a “brevity penalty” term which penalizes MT outputs shorter than reference translations. The final score is on a scale of 0 to 1.
BLEU is the most common metric to evaluate MT performance because of its many advantages: it is easy to code, very fast to compute and correlates well with human evaluation to some degree. Another benefit of using BLEU is it makes your MT engine easy to compare with others, because most MT performance is reported by using BLEU. However, one of its limitations is that it misses the semantics of translation. The underlying assumption that each source sentence has multiple reference human translations is also often difficult to meet. This means that a semantically equivalent translation that uses different words or different word order from its reference translation could be harshly penalized (e.g. paraphrases). Another issue of BLEU is that it is sensitive to tokenization. The same MT output could have different BLEU scores depending on how to tokenize the translation [15]. In recent years, as MT qualities continuously improve, increasing BLEU scores often doesn’t lead to better translation quality and using other automatic metrics is recommended. [16, 21].
2. TER (Translation Edit Rate) [17]
TER is defined as the minimum number of edits needed to change an MT output to make it exactly the same as one of the references, normalized by the average length of the references:
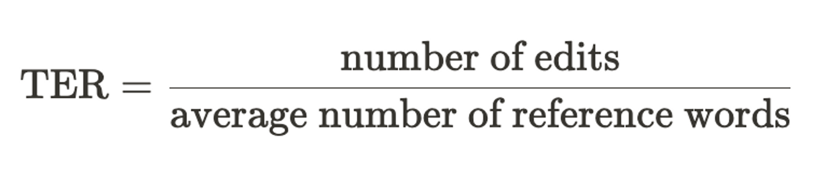
There are four types of edits: insertion, deletion, substitution of single words and shifts of word sequences. All edits are considered to have equal cost. Since calculation of minimum edit distance with the four edit operations is very expensive, an approximation is often used.
One of the appealing characteristics of TER is that its output score is interpretable: we can interpret that a TER score of 0.2 as on average 20% of MT outputs need to be edited. However, it shares the same drawback with BLEU: because it does not consider semantic equivalence, a semantically correct MT output could get a poor TER score if it is different from the surface form of the reference. To mitigate this, the authors propose HTER (Human-targeted Translation Edit Rate) in which evaluators can edit an MT output until it is fluent and has the same meaning as the human reference translation (but this HTER, obviously, is no longer an automatic procedure). In a recent study, TER has been verified to correlate with human evaluation marginally better than BLEU [16].
3. CHRF [18]
Similar to BLEU, CHRF is also based on n-gram matching. The key difference is that instead of matching word-level n-gram phrases, it matches character-level n-gram and calculates F-score based on it. Compared to BLEU, it has several advantages: It is simpler to implement than BLEU and does not require additional tools (such as a tokenizer for BLEU) or language-specific knowledge. It has been reported to have a better correlation with human evaluation than BLEU [16].
Despite their limitations, string matching-based metrics is still one of the most-widely used metrics for MT evaluation because of their efficiency and generality. In this circumstance, a question that naturally arises may be this: Is it possible for an automatic metric to be able to capture semantics of the MT output and the reference? If we go one step further, can we develop an automatic metric that outputs a similar result to the human evaluations in DA or MQM?
Metrics using Machine Learning
Recently, brilliant researchers who were trying to answer these questions have come up with several new automatic metrics that achieve these goals to some degree. Here we introduce two such metrics that make smart use of Machine Learning techniques in different ways.
1. BERTScore [19]
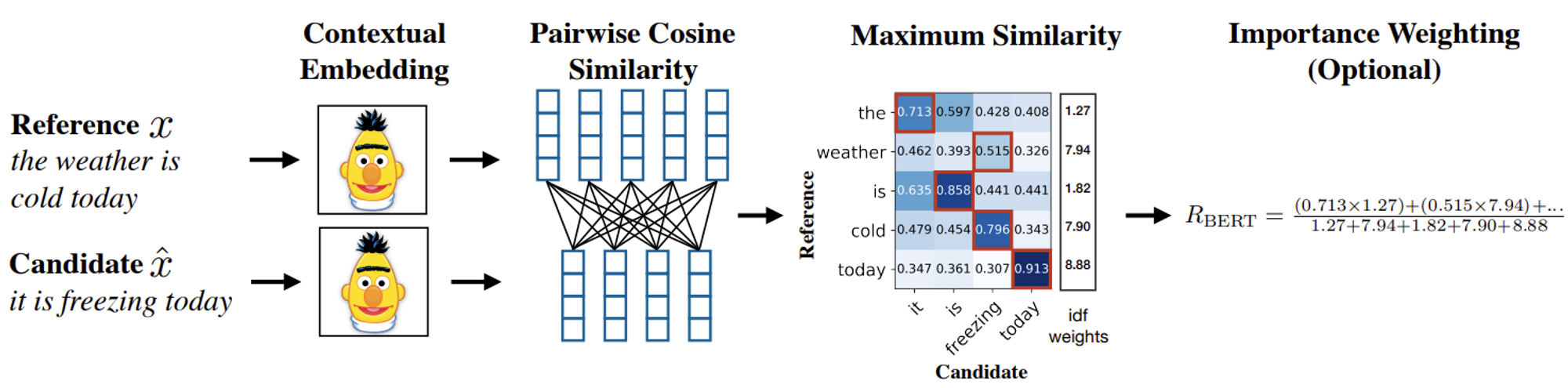
In Natural Language Processing, embedding a word or a sentence is a widely used technique to represent semantics of the input as a sequence of numbers. Training a language model on a text corpus using Machine Learning is one of the most common methods to obtain such an embedding. BERT [20] is a language model that is widely used for embedding text. It can “contextually” embed each word (or sub-tokens of a word) in the input sentence, meaning the embedding of a word is determined by its surrounding words as well as the word itself. BERTScore calculates BERT embeddings of the MT output and its reference, and matches each word in the MT output and a word in the reference whose embeddings are the most similar. It outputs an average similarity of these matched embeddings as a score.
Metrics using embeddings like BERTScore are known as embedding-based metrics. These metrics compute scores that reflect the semantic similarity of MT output and its reference, as contextual embedding models like BERT are known to capture the semantics of the inputs. BERTScore has shown higher correlation with human evaluation than string matching-based metrics [16, 19]. However, the correlation between these metrics and human evaluation could be limited, considering that many human evaluation methodologies such as DA and MQM evaluate not only semantic similarity but also other various aspects of translation qualities.
2. COMET [21]
Another group of metrics using Machine Learning is learning-based metrics which tries to directly solve the objective of automatic metrics: training ML models that learn human judgments from data. COMET is one the most successful metrics in this category. Similar to BERTScore, it uses a language model to generate embeddings of the input. However, in contrast to BERTScore, it stacks learnable layers on top of the embeddings that aim to output scores close to human judgments. The authors of COMET collected human judgment scores from various human evaluation metrics (Ranking, DA and MQM) as training data, and successfully trained COMET models that imitate scores from human judgment.
One noticeable characteristic of COMET is that it takes the source sentence into account when calculating a score. In the initial COMET experiments, including the source improved the correlation with human judgment. This also enables COMET-QE, a variant COMET for reference-less MT evaluation where the quality of an MT output is measured given the source sentence only [22].
Learning-based metrics have been increasingly adopted as an automatic MT evaluation tool, and research works have confirmed that COMET is one of the best automatic metrics for MT evaluation developed so far [16, 23]. However, depending on the domain and test data, it is not always highly correlated with human evaluation [23].
There is no doubt that the development of automatic MT evaluation metrics has greatly contributed to the rapid development of MT. Nonetheless, developing automatic metrics that perfectly correlates with human judgment is still an open problem. With the budget and time constraints that most MT developers are inevitably facing in mind, the best strategy to evaluate MT systems as reliably as possible would be in combining both automatic metrics and human judgments in the MT development cycle. On top of that, it is also important to design a human evaluation method according to the type of translation quality required by the stakeholder. In the next section we will introduce how XL8 evaluates our MT engines, and what makes our evaluation strategy most suitable for measuring the performance of MT systems for localization business.
XL8 MT evaluation
XL8 is providing MT for more than 70 language pairs at the time of writing, and is continuously updating existing engines and adding new language pairs. An accurate and interpretable evaluation of each one of these engines is very important to us for two reasons:
- To make sure a newly developed engine works well.
- To showcase the performance of our MT systems to customers in an intuitive manner.
With these points in mind, we designed our human evaluation to satisfy the below conditions:
- Do not use a publicly available dataset as testing data.
- Make human evaluation done by professional translators.
- Calculate accuracy by the percentage of MT outputs that are correct at a sentence level.
Condition 1 is to completely block the possibility of (both intentional and unintentional) unfairness. Some customers are interested in evaluation results from a well known public dataset such as WMT or IWSLT data. However, evaluation results should not be corrupted by any possible unfair conditions. Because any public dataset could be part of training data for an external MT system with which we compare ours, excluding public data is mandatory to avoid unexpected unfairness in the evaluation. Another problem with public datasets is a mismatch of domains: evaluating XL8’s MT engines specifically designed for media content and colloquial texts against biomedical documents would not make much sense, for example. For all XL8 human evaluations, the testing data is independently collected by a team isolated from the MT engine development which lets us ensure fair and unbiased evaluation.
Condition 2 is to increase the credibility of the evaluation as much as possible. As mentioned in Section 2, the quality of human evaluation done by non-experts is often noisy and inconsistent. To prevent this, for each human evaluation we hire professional translators who are native speakers of the target language and also are fluent in the source language.
Lastly, Condition 3 is to make the evaluation simple as well as rigorous. An MT output for each input sentence is marked as correct only when the entire translation is correct, and is marked as incorrect otherwise. This criterion is simpler than DA or MQM so that the evaluation process can be faster and more efficient. At the same time, it is very challenging for MT systems because it is impossible to get partial credits from imperfect translations. The evaluation result can be summarized as an accuracy of sentence-level translation which is quite intuitive and interpretable (for example, 80% accuracy means 80 out of 100 translated sentences are correct). Also, this scoring can be used to measure the relative qualities of MT systems (by ranking MT systems using the accuracy numbers) as well as the absolute quality.
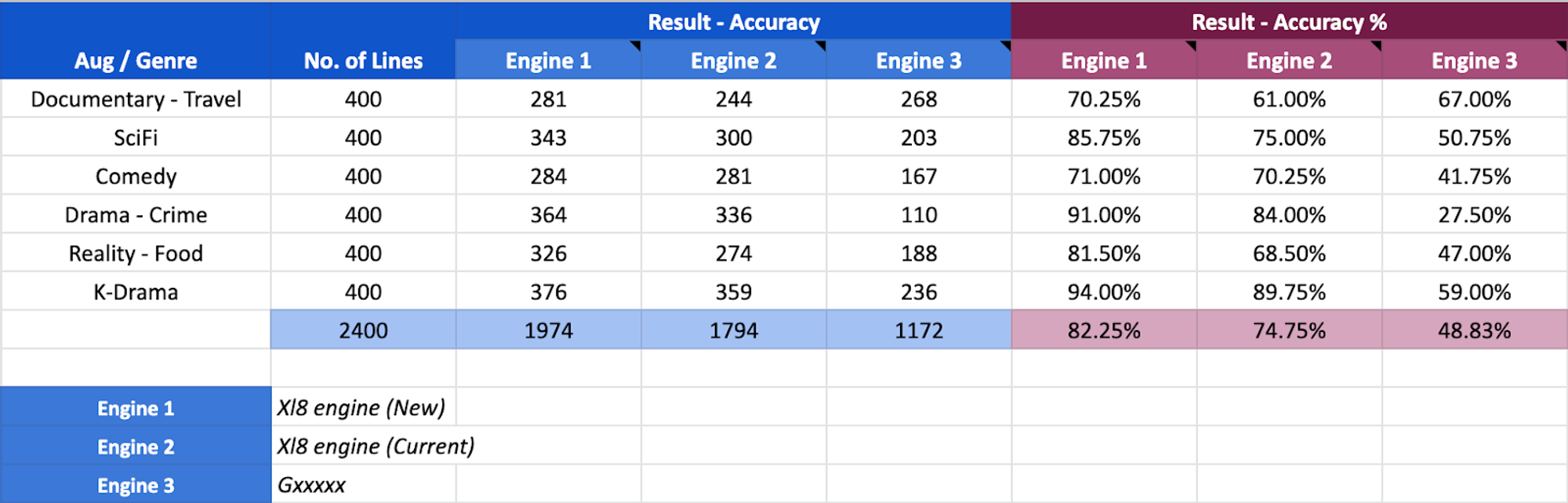
For every major update of an existing engine or release of an engine for a new language pair, XL8 conducts the human evaluation described above with 2400 sentences collected from six different genres: Documentary, Drama, Sci-fi, Reality, Comedy and K-Drama. For evaluation in the middle of an engine development or for a confirmation procedure before heading to a human evaluation, we use various automatic metrics such as BLEU, CHRF and COMET. This hybrid approach of automatic and human evaluation allows us to optimize our time and budget and at the same time obtain accurate and interpretable evaluation scores.
We believe accuracy numbers of correctly translated sentences on various media genres is an informative indicator of the effectiveness MT on localization business. XL8’s MT systems outperformed most competitors by a large margin in the XL8 human evaluations conducted for 30 language pairs, and showed a higher than 70% percentage of accuracy for 20 language pairs. Our latest engine updates with context awareness also showed up to 30 percent improvements. For more detailed testing results, please check our website!
Conclusion
Evaluating MT systems in a rigorous and efficient manner is as challenging as developing a perfect MT system. In this blog post, we briefly reviewed why it is so difficult, a few representative human judgments and automatic evaluation methodologies and their pros and cons. We also introduced XL8’s approach to evaluate our MT systems with an outcome that is both accurate and easily interpretable. On XL8 human evaluations, most of XL8’s MT systems outperformed competitors by a significant margin.
This post ends here, but the story of XL8’s MT has just begun. As MT and its evaluation continuously advances, XL8’s efforts to improve our MT systems and evaluation process will also continue. We urge the readers to follow our future updates on these subjects, and we promise they will come with greater translation quality improvements!
‣ References
- White, J. S. and O’Connell, T. A. (1996). Adaptation of the DARPA machine translation evaluation paradigm to end-to-end systems. In Conference of the Association for Machine Translation in the Americas, Montreal, Canada.
- Koehn, P. and Monz, C. (2006). Manual and automatic evaluation of machine translation between Euro- pean languages. In Proceedings on the Workshop on Statistical Machine Translation, pages 102–121, New York City. Association for Computational Linguistics.
- David Vilar, Gregor Leusch, Hermann Ney, and Rafael E. Banchs. 2007. Human evaluation of machine translation through binary system comparisons. In Proceedings of the Second Workshop on Statistical Machine Translation, pages 96–103.
- Chris Callison-Burch, Philipp Koehn, Christof Monz, Josh Schroeder, and Cameron Shaw Fordyce. 2008. Proceedings of the Third Workshop on Statistical Machine Translation. In Proceedings of the Third Workshop on Statistical Machine Translation.
- Graham, Y., Baldwin, T., Moffat, A., and Zobel, J. (2013). Continuous measurement scales in human evaluation of machine translation. In Proceedings ofthe 7th Linguistic Annotation Workshop and Inter- operability with Discourse, pages 33–41, Sofia, Bulgaria. Association for Computational Linguistics.
- Ondrej Bojar, Rajen Chatterjee, Christian Federmann, Yvette Graham, Barry Haddow, Shujian Huang, Matthias Huck, Philipp Koehn, Qun Liu, Varvara Logacheva, Christof Monz, Matteo Negri, Matt Post, Raphael Rubino, Lucia Specia, andMarco Turchi. 2017. Findings of the 2017 Conference on Machine Translation (WMT17). In Second Conference on Machine Translation, pages 169–214. The Association for Computational Linguistics.
- Lo¨ıc Barrault, Magdalena Biesialska, Ondˇrej Bojar, Marta R. Costa-juss`a, Christian Federmann, Yvette Graham, Roman Grundkiewicz, Barry Haddow, Matthias Huck, Eric Joanis, Tom Kocmi, Philipp Koehn, Chi-kiu Lo, Nikola Ljubeˇsi´c, Christof Monz, Makoto Morishita, Masaaki Nagata, Toshiaki Nakazawa, Santanu Pal, Matt Post, and Marcos Zampieri. 2020. Findings of the 2020 Conference on Ma- chine Translation (WMT20). In Proceedings of the Fifth Conference on Machine Trans- lation, pages 1–55, Online, Association for Computational Linguistics.
- Arle Lommel, Hans Uszkoreit, and Aljoscha Burchardt. 2014. Multidimensional quality metrics (MQM): A framework for declar- ing and describing translation quality metrics. Tradum`atica, pages 455–463.
- Mariana, V., Cox, T., and Melby, A. (2015). The Multidimensional Quality Metrics (MQM) framework: a new framework for translation quality assessment. The Journal of Specialised Translation, pages 137–161.
- Freitag, M., Foster, G., Grangier, D., Ratnakar, V., Tan, Q., and Macherey, W. (2021). Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation. Transactions of the Association for Computational Linguistics, 9:1460–1474.
- Leiter, C., Lertvittayakumjorn, P., Fomicheva, M., Zhao, W., Gao, Y., & Eger, S. (2022). Towards Explainable Evaluation Metrics for Natural Language Generation. arXiv preprint arXiv:2203.11131.
- Zerva, C., Glushkova, T., Rei, R., & Martins, A. F. (2022). Better Uncertainty Quantification for Machine Translation Evaluation. arXiv preprint arXiv:2204.06546.
- Zerva, C., Glushkova, T., Rei, R., & Martins, A. F. (2022). Better Uncertainty Quantification for Machine Translation Evaluation. arXiv preprint arXiv:2204.06546.
- Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002, July). Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics (pp. 311-318).
- Post, M. (2018). A call for clarity in reporting BLEU scores. arXiv preprint arXiv:1804.08771.
- Kocmi, T., Federmann, C., Grundkiewicz, R., Junczys-Dowmunt, M., Matsushita, H., & Menezes, A. (2021). To ship or not to ship: An extensive evaluation of automatic metrics for machine translation. arXiv preprint arXiv:2107.10821.
- Snover, M., Dorr, B., Schwartz, R., Micciulla, L., & Makhoul, J. (2006). A study of translation edit rate with targeted human annotation. In Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers (pp. 223-231).
- Popović, M. (2015, September). chrF: character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation (pp. 392-395).
- Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., & Artzi, Y. (2019). Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675.
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. COMET: A Neural Framework for MT Evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Process- ing (EMNLP), pages 2685–2702, Online. Associa- tion for Computational Linguistics.
- Rei, R., Farinha, A. C., Zerva, C., van Stigt, D., Stewart, C., Ramos, P., ... & Lavie, A. (2021, November). Are references really needed? unbabel-IST 2021 submission for the metrics shared task. In Proceedings of the Sixth Conference on Machine Translation (pp. 1030-1040).
- Freitag, M., Rei, R., Mathur, N., Lo, C. K., Stewart, C., Foster, G., ... & Bojar, O. (2021, November). Results of the WMT21 metrics shared task: Evaluating metrics with expert-based human evaluations on TED and news domain. In Proceedings of the Sixth Conference on Machine Translation (pp. 733-774).
Written By Kang Kim, Head of Research at XL8 Inc.
Contributors
Kai Kim
Head of Research


