
My Experience on Improving a Feature for XL8’s Subtitle Editor as an Intern
As I entered the final semester of my university journey, a unique opportunity presented itself – an internship with XL8 as a frontend engineering intern. In this blog post, I am excited to share the experience with my first project, which was about improving a feature in one of the MediaCat’s functionalities - called the Editor.
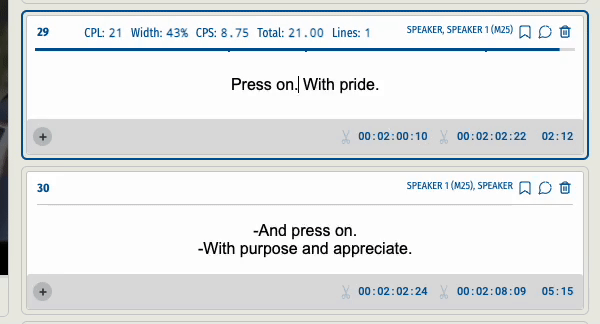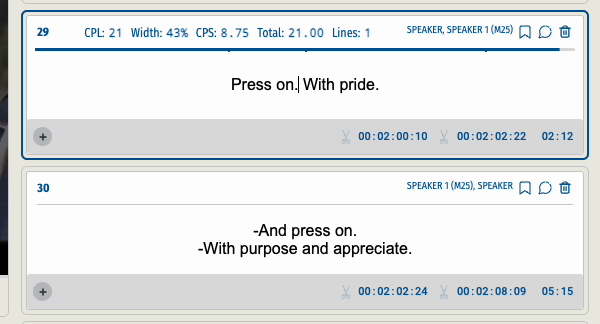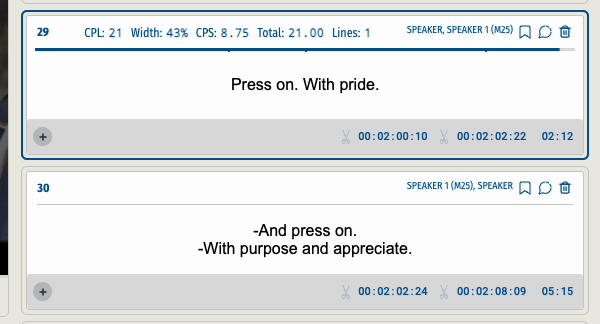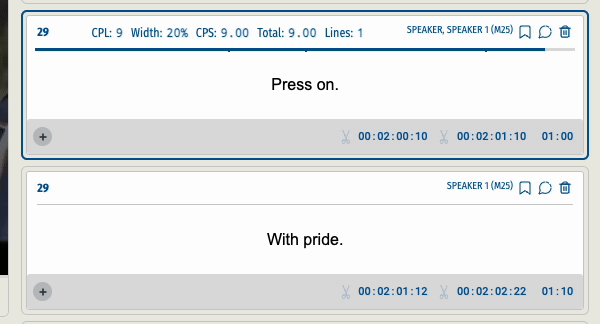
When a user split a subtitle segment into two the end time code of the first segment and the start time code of the second segment were not accurate. Users needed to go back to the video to precisely capture the newly created ‘edges’.
Before delving into the details of the improvement, let me first explain the challenge we aimed to address.
Within our service, "MediaCAT," users have the ability to split or merge subtitle segments (individual sentences) at their discretion. Merging segments posed minimal challenges, as we could easily determine the starting and ending time codes of the first and second segments. However, when it came to splitting a single segment, we encountered a more complex problem.
To provide users with accurate information on where the segment had been split, we needed to generate a new time code. Traditionally, this was done by calculating the time code proportionally based on the number of words in the segment. This method sometimes lacked precision, leading to inaccuracies in the timing of split segments.
The solution we devised was to leverage the power of artificial intelligence. Our plan involved implementing an AI system capable of detecting the timecode for every individual word throughout the entire script. By storing this data, we would have the ability to furnish users with precise time codes whenever they chose to split segments. This provides a much more accurate distribution of timecodes when sentences are split, significantly reducing the need for users to manually adjust cue-in and cue-out points. Moreover, if the system encounters scenarios where it can't determine the precise word-level timecode—such as with newly introduced words—it's designed to provide the closest possible timecode approximation, ensuring the split remains as accurate as possible.
In the course of this endeavor, I encountered hurdles and gained invaluable lessons and I would like to share it through this post.
Getting the anchor index from a multiple line segment.
We are discussing migration to Lexical, but currently the service is based on Draft.js. It was my first time working with the library, and the most important property of Draft.js - editor state and content state - was quite difficult to get through at first. The real challenge during the process of implementation was since our API was designed to send the time code data by each word’s index, I had to get the index of the word where the user’s mouse pointer resided. At first I didn’t think it would be a big task at all. But since Draft.js stored the state line-by-line, I needed the following code to get the index of the word.

‘getPlainText()’ returns the full plainText value of the contents, joined with a delimiter-in this case ‘\n’. After getting an array of lines in a segment, I had to add up the length of each line prior to the specific index using the reduce method.
Minimum interval between subtitles
Another critical lesson emerged regarding the minimum interval between subtitles, inspired by Netflix's industry standard of maintaining a 2-frame gap between subtitles. Our AI model initially lacked awareness of this requirement, occasionally generating identical in and out time codes for two continuous words. Solving this issue necessitated calculating and adjusting the minimum value that needed to be added or subtracted from two words to ensure the requisite 2-frame gap.
Trivial but important things that I have learned.
I gleaned some essential but often overlooked lessons about coding and teamwork. While these may seem basic to some, they proved pivotal in my growth as a software engineer.
1. Do not write short forms for names of variables
First, I learned the importance of using descriptive variable names rather than relying on short forms like 'idx' or 'cnt.' Clarity and understandability take precedence over brevity.
2. Final newline
All text files should end with a newline since that is how the POSIX standard defines a line.
3.206 Line
A sequence of zero or more non- <newline> characters plus a terminating <newline> character.
Upon that, Adding a final newline is good since it removes needless differences which produce cleaner commits and reduces unnecessary cognitive load when reviewing pull requests.I was not aware of this, and made a few mistakes saving files without a final newline, or even deleting the existing final newline. This knowledge, kindly imparted by my team, has become a part of my coding ethos.
Result
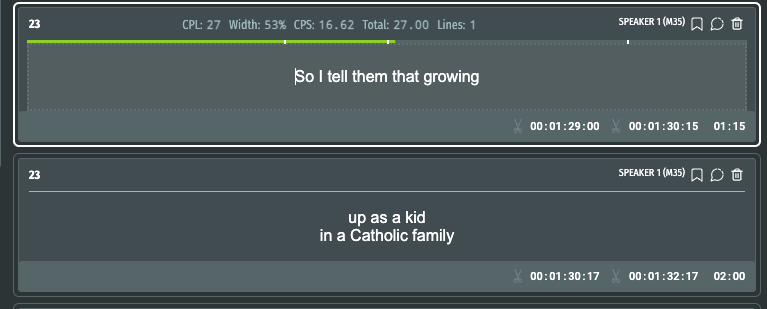
This was the result of splitting a segment before and after the update.
Before :
After :
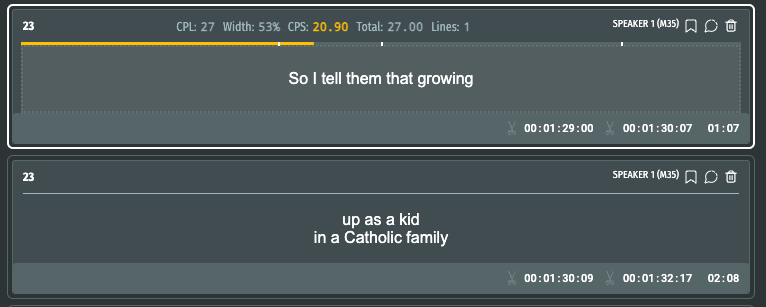
Prior to the update, the time code, calculated based on the proportion of words, stood at '00:01:30:15.' However, with the assistance of XL8's AI technology, it now reads '00:01:30:07,' demonstrating a tangible improvement that greatly benefits our users.
In conclusion, my journey as an intern at XL8 has been one of both technical growth and personal development. The opportunity to contribute to the enhancement of XL8's core service has deepened my understanding of the immense potential of AI in the world of subtitles and translations. As I look back on this transformative experience, I am excited about the possibilities that lie ahead for both XL8 and myself in this dynamic field. Currently I am working on a new project and I will be happy to share my experience once more once it is deployed.
Contributors
Jinnie
Frontend Team Intern


