
Review of "Enhanced Simultaneous Machine Translation with Word-level Policies"
Introduction

Recently, a paper titled “Enhanced Simultaneous Machine Translation with Word-level Policies” [1], authored by research scientists at XL8, was accepted for the Findings of EMNLP. In this blog, I will review the paper and offer a glimpse into how XL8 achieves high performance in simultaneous machine translation (SiMT).
Deep dive on the paper
The main ideas of the paper can be summarized into four subjects: the suggestion to use word-level evaluation methods, the utilization of word-level policies, intra-word bidirectional encoding, and the integration of language models (LM) into SiMT. Let's first examine how most existing SiMT models work, then delve into the details of each subject, and review the results.
How most existing SiMT models work
SiMT differs from offline machine translation in that it initiates translation before the full source sentence is available. Therefore, it's crucial to design a method to determine when to read and when to write, a process known as 'policy'. These policies can be divided into two categories: fixed policy and adaptive policy. A fixed policy determines when to read and write based on predefined rules. For instance, Wait-k [2] models initially read k tokens, then alternate between writing and reading one token. In contrast, adaptive policies decide when to read and write based on the source and the target tokens read and written so far.
Although the actual inputs and outputs of SiMT systems are a sequence of words, most existing SiMT systems design their policies at the token level, regardless of whether they are fixed or adaptive policies.
Suggestion to use word-level evaluation methods
The conventional token-level policies pose a problem when evaluating the performance of SiMT models, as different models use various tokenization methods, making it difficult to compare the performance of token-level policies. One of the most widely used evaluation methods in SiMT is Average Lagging (AL) [2], which measures the average number of source tokens read for each target token written. Thus, in the paper, we suggested using word-level evaluation methods. Specifically, we recommended word-level AL, which measures the average number of source words read for each target word written.
Utilization of word-level policies
The token-level policies also exhibit inefficiency in writing target tokens before finishing reading the source words. As mentioned earlier, the unit of input is a sequence of words, and under the same word-level latency, token-level policies may not process all the tokens in a source word, potentially leading to incorrect translation of these tokens. Moreover, completing the writing of target tokens before the end of the target word could pose another problem, as the outputs should be complete words. Displaying unfinished words might cause issues in certain contexts.
Therefore, we proposed a word-level policy to ensure that the policy reads and writes entire source and target words, respectively. By using the word-level policy, SiMT models can process more source tokens under the same word-level latency and can translate more accurately as the model translates entire source words, not just subwords. One advantage of the word-level policy is its adaptability; any existing token-level policy can be transformed into a word-level policy by simply adjusting the read and write operations to conclude at the end of source and target words.
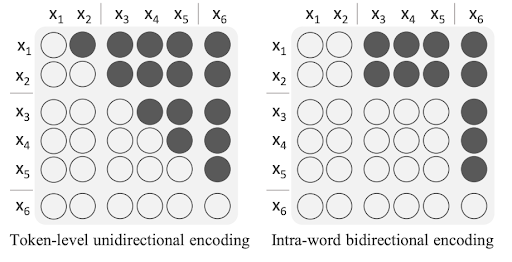
To eliminate redundant recomputation in encoders, it is common to use unidirectional encoding [3] in SiMT, so that only the attention for new source tokens needs to be recalculated. Since most existing SiMT models employ token-level policies, their unidirectional masking is also at the token level. However, this approach has some inefficiencies as the unit of inputs is words, and there is potential to utilize bidirectional encoding among tokens within the same word. In the paper, we refer to this approach as 'Intra-word bidirectional encoding'.
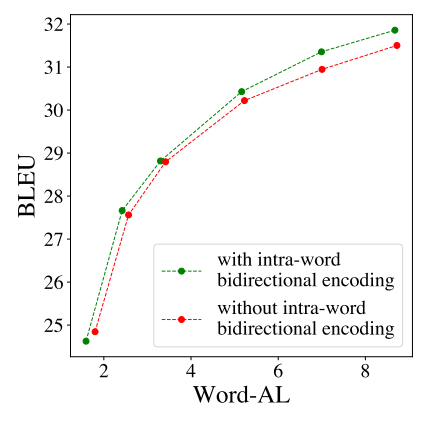
The impact of Intra-word bidirectional encoding is illustrated in Figure 3. As can be seen in the graph, the word-level model with intra-word bidirectional encoding consistently outperformed the word-level model without intra-word bidirectional encoding in all word-level average lagging.
Integration of LMs into SiMT models
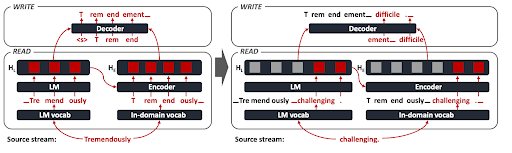
Another benefit of using word-level policies is their ability to handle vocabulary mismatches between the SiMT model and existing LMs. When integrating LMs into SiMT models with token-level policies, finding an optimal solution was challenging due to differences in tokens between the LM and SiMT. However, with word-level policies, integration becomes straightforward by designing a word-level causal mask. Although there are various methods to integrate LMs, in the paper, we adopted the method suggested by [4]. We adopted the method by transforming the BERT model into a decoder-only language model, enabling unidirectional encoding, and applying a word-level causal mask between each LM-encoder attention and LM-decoder attention.
Results
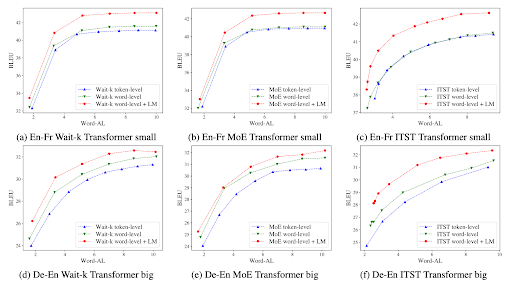
In the paper, we applied word-level policies to three existing models. Among them, Wait-k [2] and MoE(Wait-k) [5] utilize a fixed policy, while ITST [6] utilizes an adaptive policy. As illustrated in Figure 5, word-level policies consistently outperformed token-level policies in almost all dataset-model combinations. Furthermore, word-level models with LM integration outperformed those with only word-level policies in all dataset-model scenarios. These results verify the effectiveness of the methods suggested in our paper.
Conclusion
We've just skimmed the surface of the paper in this review. For those interested in the finer details, we suggest reading the full paper for a deeper understanding.
Here at XL8, we're constantly working to make simultaneous machine translation (SiMT) better. The techniques we've discussed from the paper are part of a larger set of tools we use to improve SiMT. We're always on the lookout for new ways to enhance these systems.
Our work in improving SiMT is an ongoing process, and we're excited about what the future holds. Stay tuned for more updates from us on both SiMT and offline machine translation. We're committed to making translation more effective and accessible, and we look forward to sharing our progress with you.
References
[1] Kang Kim and Hankyu Cho. 2023. Enhanced Simultaneous Machine Translation with Word-level Policies. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 15616–15634, Singapore. Association for Computational Linguistics.
[2] Mingbo Ma, Liang Huang, Hao Xiong, Renjie Zheng, Kaibo Liu, Baigong Zheng, Chuanqiang Zhang, Zhongjun He, Hairong Liu, Xing Li, Hua Wu, and Haifeng Wang. 2019. STACL: Simultaneous Translation with Implicit Anticipation and Controllable Latency using Prefix-to-Prefix Framework. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3025–3036, Florence, Italy. Association for Computational Linguistics.
[3] Maha Elbayad, Laurent Besacier, and Jakob Verbeek. 2020. Efficient Wait-k Models for Simultaneous Machine Translation. In Proc. Interspeech 2020, pages 1461–1465.
[4] Jinhua Zhu, Yingce Xia, Lijun Wu, Di He, Tao Qin, Wengang Zhou, Houqiang Li, and Tie-Yan Liu. 2020. Incorporating bert into neural machine translation. arXiv preprint arXiv:2002.06823.
[5] Shaolei Zhang and Yang Feng. 2021. Universal simultaneous machine translation with mixture-of-experts wait-k policy. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7306–7317, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
[6] Shaolei Zhang and Yang Feng. 2022b. Information transport-based policy for simultaneous translation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 992– 1013, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
Contributors
Matthew Cho
Research Engineer


