
The Augmented Human Being: Large JavaScript File Refactoring Experience Through Three-Way Collaboration with AI, Code, and Human
Common Mistakes Made by ChatGPT Beginners
It's been about a year since OpenAI released the GPT-4 model for ChatGPT. During this time, observing how newcomers interact with ChatGPT has been quite revealing. Initially, people are astounded by ChatGPT's ability to respond intelligently to even the most nonsensical questions as if it were a human. Then, they bring their complex real-world problems to ChatGPT, hoping for solutions. Typically, they make three common mistakes:
- Expecting ChatGPT to provide the right answers right away.
- Expecting ChatGPT to provide right answers right away.
- Feeling disappointed when expectations 1 and 2 are not quickly met, leading them to only use ChatGPT for relatively simple problems (e.g., button label suggestions), use it passively (e.g., VSCode Copilot), or stop using it at all.
As a result, many miss out on opportunities to enhance everyday productivity with AI.
Ironically, this was me until a few months ago. I thought I became much better at prompting after attending a Cognitive Prompting session held by June Kim, an agile software development coach renowned in Korea. But I found myself making the exact same mistakes when trying to use ChatGPT for development problems at work.
However, upon realizing these mistakes and shifting my strategy, I came to appreciate that, although ChatGPT might not always provide the answers immediately, it can still offer incredible assistance. This strategy revolves around the collaboration among AI + Code + Humans mentioned in the title.
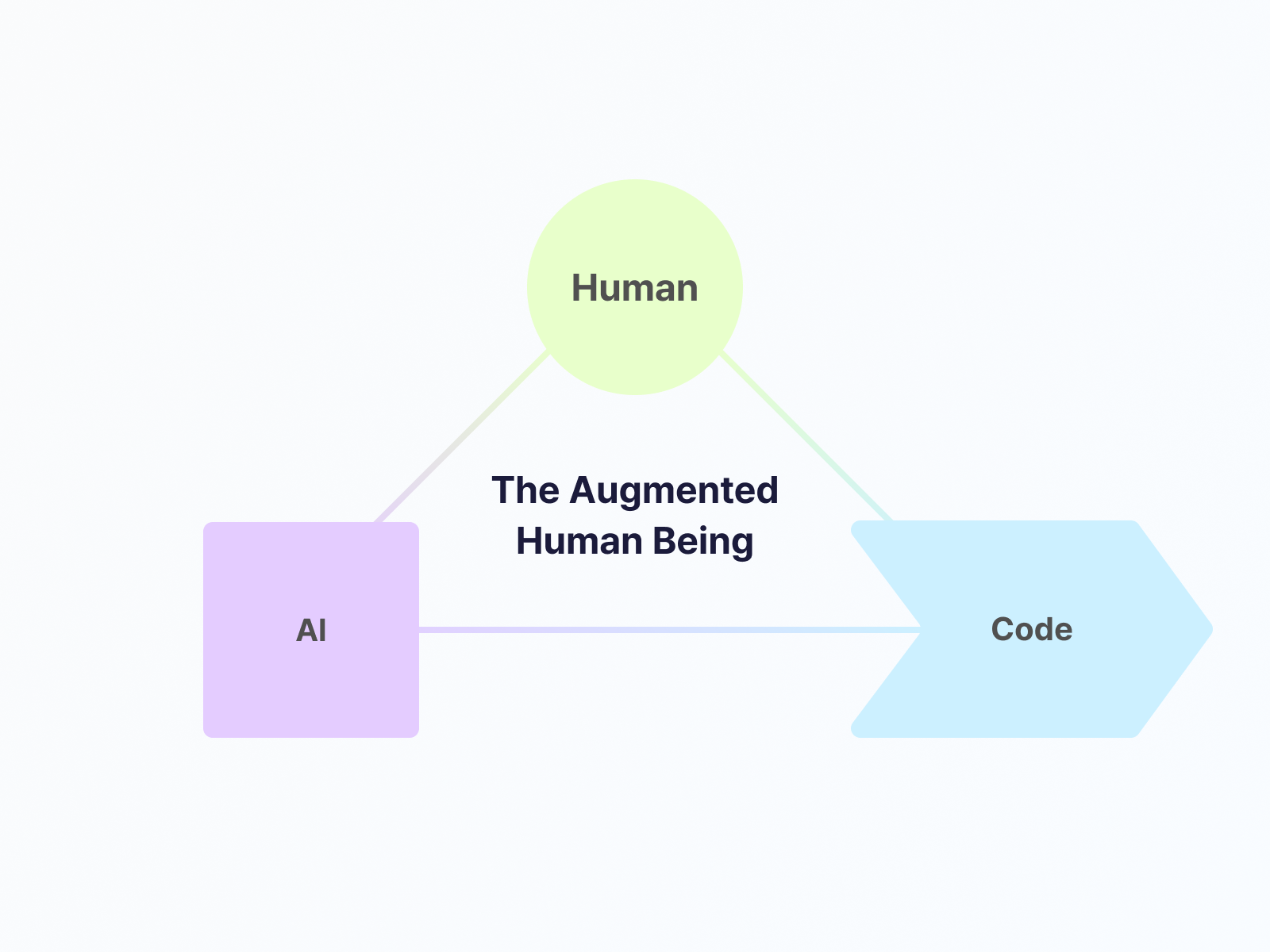
This tripartite collaboration strategy emphasizes the mental model that June Kim consistently highlighted during the Cognitive Prompting session. I'll share how I applied this mental model to the problems I faced and how it differs from expecting 'correct answers' from ChatGPT.
The Problem Faced
MediaCAT, a product I’m in charge of at XL8, includes a built-in subtitle editor. It’s built-in from a user's perspective, but the subtitle editor is technically housed in a separate code repository. With customer demands for the subtitle editor increasing since the start of the year, I shifted my primary focus towards the editor and began to delve into its code.
One of the main pieces of feedback from editor users was about the slow initial loading speed. Indeed, this editor has been developed over a very long period. It includes a lot of features and, by modern standards, a lot of inefficient code. Additionally, since the editor was originally designed for workflows involving human translators working from scratch, many lines of code became unnecessary as the workflow transitioned to machine translation followed by post-editing. It was no wonder the loading speed was slow.
Before embarking on a major performance improvement effort, I looked for low-hanging fruit. The first step was measuring the bundle size. Upon measurement, I found that the main chunk size of our subtitle editor was an enormous 6.89MB unzipped which was a staggering size.
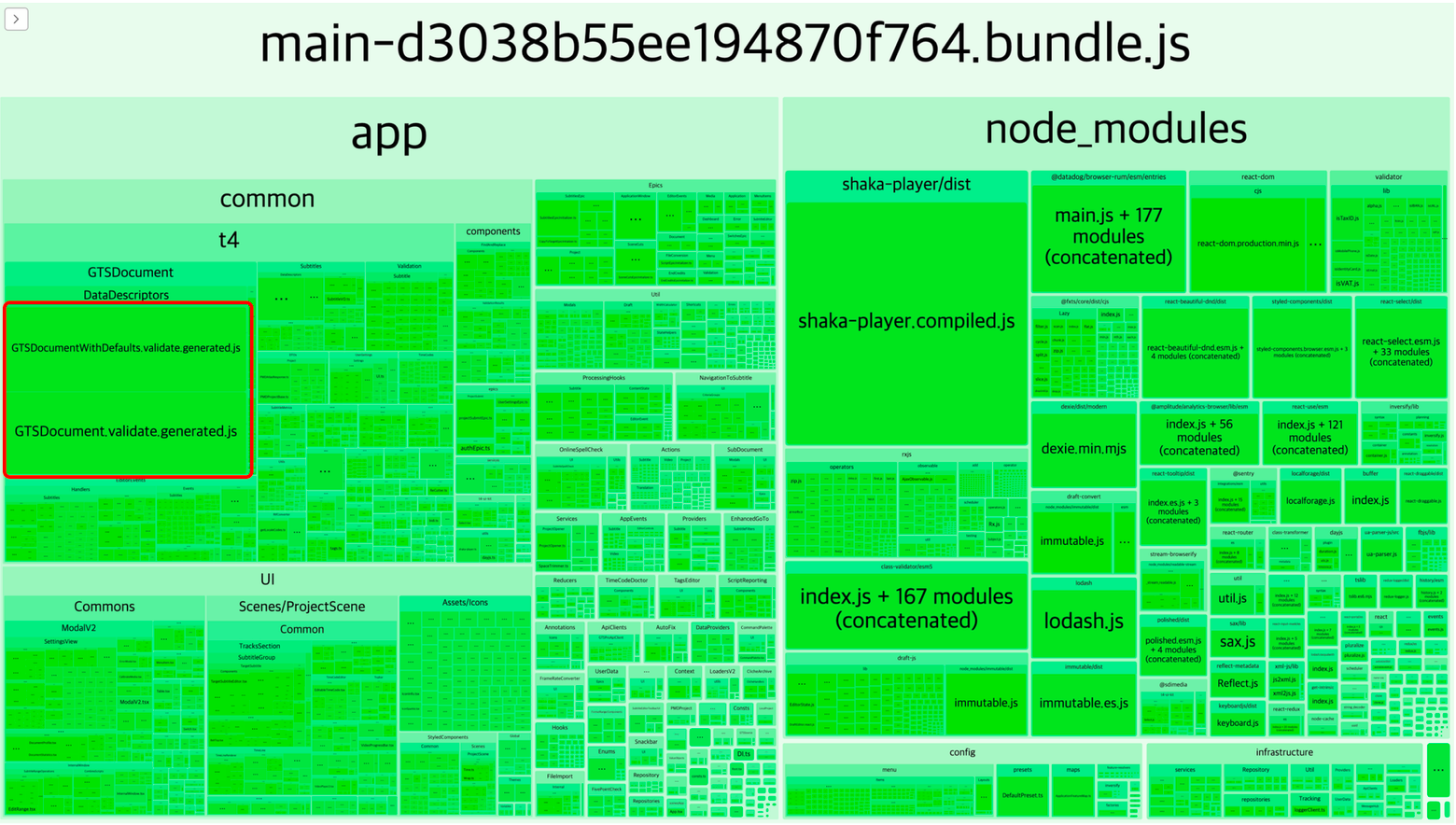
But aside from node_modules, there were also two incredibly large files, file A and file B , within our app itself. These files existed in a minified state within the repository, yet their combined size exceeded 700KB. This was over 10% of the main chunk's size, which raised doubts about their necessity in our current business logic.
Upon un-minifying both files for a closer examination, I learned several things:
- The role of file A and file B was nearly identical (over 90% code duplication), designed to validate the subtitles' validity during the initial loading process in the editor.
- In our current workflow, where subtitles are not directly uploaded by users but generated after MediaCAT's preprocessing, "validation" was unnecessary. Therefore, file A could be deleted, and the validation process could be skipped.
- However, executing file B did more than just validation; it also caused side effects by setting certain default values (e.g., font size, color, position) if they were not already set in the subtitle. Thus, this file couldn't just be deleted; the code for setting default values needed to be retained.
Although the un-minified version of file B was a whopping 18,500 lines long, I thought it manageable to manually remove unnecessary parts by comparing it with file A. However, this task proved far from easy, given the sheer volume of lines. It was incredibly tedious, sleep-inducing, and error-prone. With the file's length, verifying how far I had accurately edited was also challenging. It was then I wondered if ChatGPT could handle this repetitive and tedious task efficiently.
1st Attempt: Hey ChatGPT, Refactor This for Me
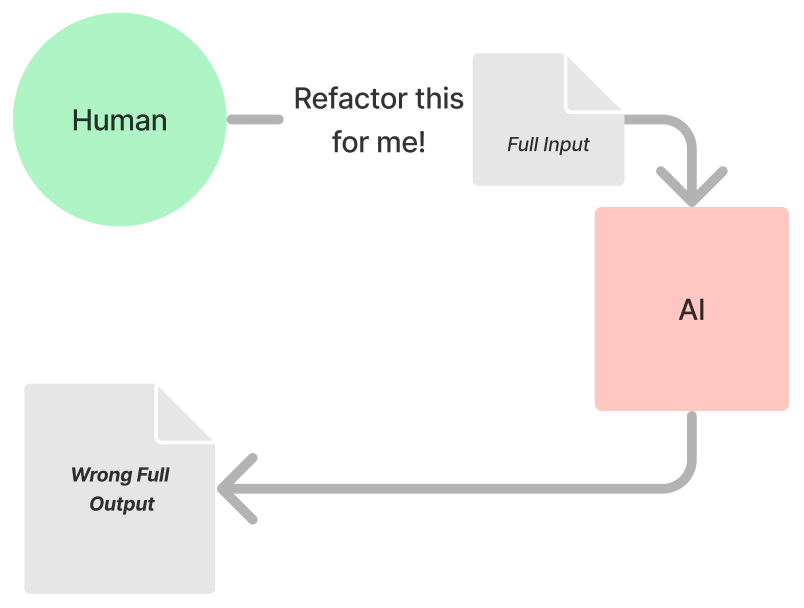
Inside file B, there were several functions spanning over 1000+ lines. For my first attempt, I chose one of these functions and asked ChatGPT to refactor it. Since I had already refactored it myself, this function served as a benchmark to verify the effectiveness of ChatGPT's refactoring.
I employed cognitive prompting; assigning roles, explaining the context, providing examples, and taking a step-by-step approach. Up until this point, I was quite confident. I felt good about how well I had crafted the prompt.
"You are an expert Javascript developer who has special expertise on refactoring and cleaning legacy codes. You have a long js file with several functions, each of which takes an object to validate whether the given data follows a certain pattern.
You realized that this validation is not needed any more in your codebase, so you want to delete it. But you also found that some validator functions include side effects that mutate the given data to have some default values. Each function may contain 1000+ lines of code.
Now you want to only remove the validation part, preserving the setting defaults part.
For example, this is some part of a function.
(example follows)
I'll give you a js file which has the function to clean.
How would you resolve this issue with your expertise? Think step by step, and show me your intermediate steps to issue."
ChatGPT seemed to understand the situation well and discussed the steps it would take for refactoring, so I sent over the actual file containing just the target function. Internally, it generated Python code and began the refactoring process earnestly.
The process took a while, and my expectations were high. However, when I received a link to download the result and reviewed it, it was a disappointment. Not only had it failed to remove parts that should have been deleted, but it also produced code that wouldn't compile. For instance, like this:

Overall, rather than understanding and modifying the code structure, it seemed to simply delete lines sequentially. Despite several rounds of error pointing and requests for re-attempts, all efforts failed. It became strongly evident that this approach was not going to work.
2nd Attempt: Hey ChatGPT, Write Code to Refactor
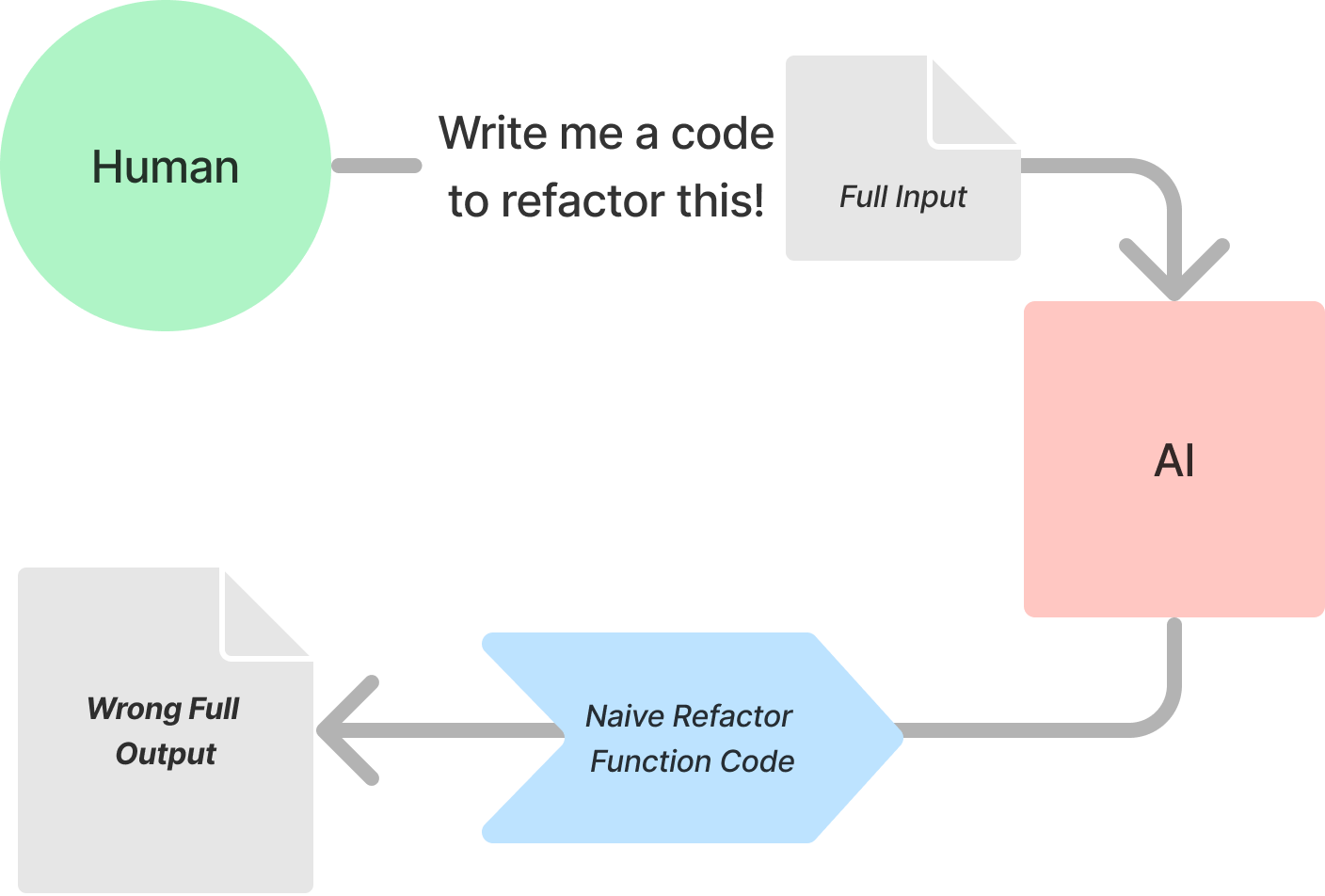
So, I decided to ask for JavaScript code that could accomplish the refactoring according to my intentions.
"You still fail to remove all the unneeded codes. Instead, can you provide a javascript code to refactor this function as my intention?"
However, the code ChatGPT produced was disappointingly inadequate. It seemed like a direct translation of the Python code used internally in the first attempt into JavaScript.

Seeing this made me realize why directly asking ChatGPT to perform the refactoring wasn't yielding good results. The reason, in hindsight, appears obvious. ChatGPT is a Large Language Model (LLM) developed by learning from documents available on the web. But were there enough examples on the web of the kind of sophisticated refactoring I wanted, complete with before and after snapshots of the code? Probably not.
3rd Attempt: Hey ChatGPT, Write Code to Refactor Using AST
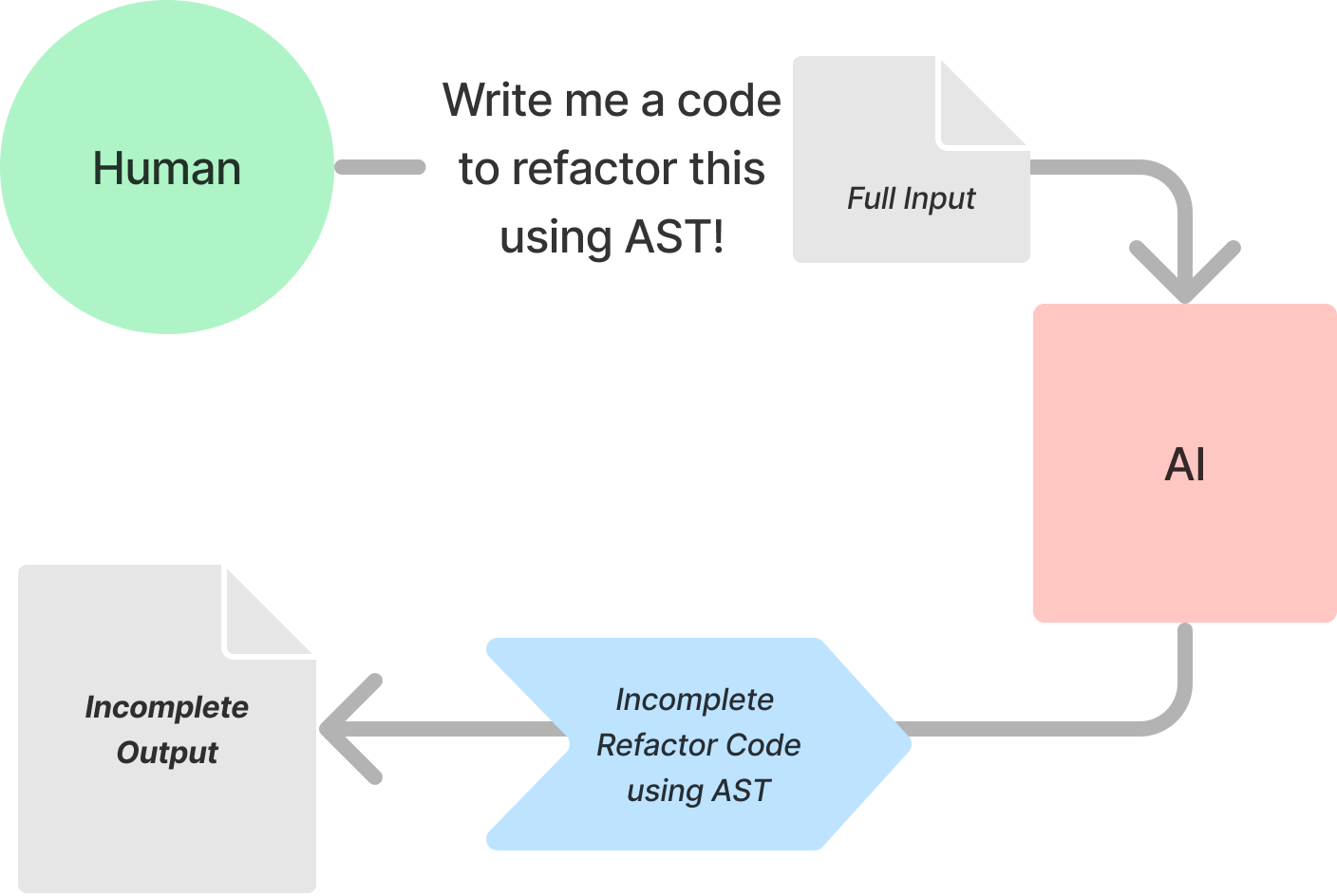
I didn't just want to delete lines of code on a line-by-line basis; I wanted to remove entire 'blocks', such as if statements, based on certain conditions. This required understanding the functions syntactically, which led me to consider using Abstract Syntax Trees (AST).
So, this time, I asked ChatGPT, as an expert in various fields, to introduce me to an expert capable of writing code to refactor long functions. I also mentioned that I was keeping AST in mind. The response was quite promising, recommending professionals like compiler engineers and static analysis tool developers.
Then I requested ChatGPT to create a code with AST that refactors my functions, as an engineer experienced with static analysis tools like ESLint. Here’s the part of the response :

As you can see, it was an impressive piece of code based on babel. I began to understand how to traverse and identify which syntax and conditions required removal of certain elements. It was a significant breakthrough.
However, the issue was my lack of experience in handling babel as an AST. I wasn't confident in crafting the 'what to remove under which conditions' logic precisely with babel. I wasn't keen on learning babel from scratch, so I first asked ChatGPT how it would write an isValidationLogic for refactoring my specific function :
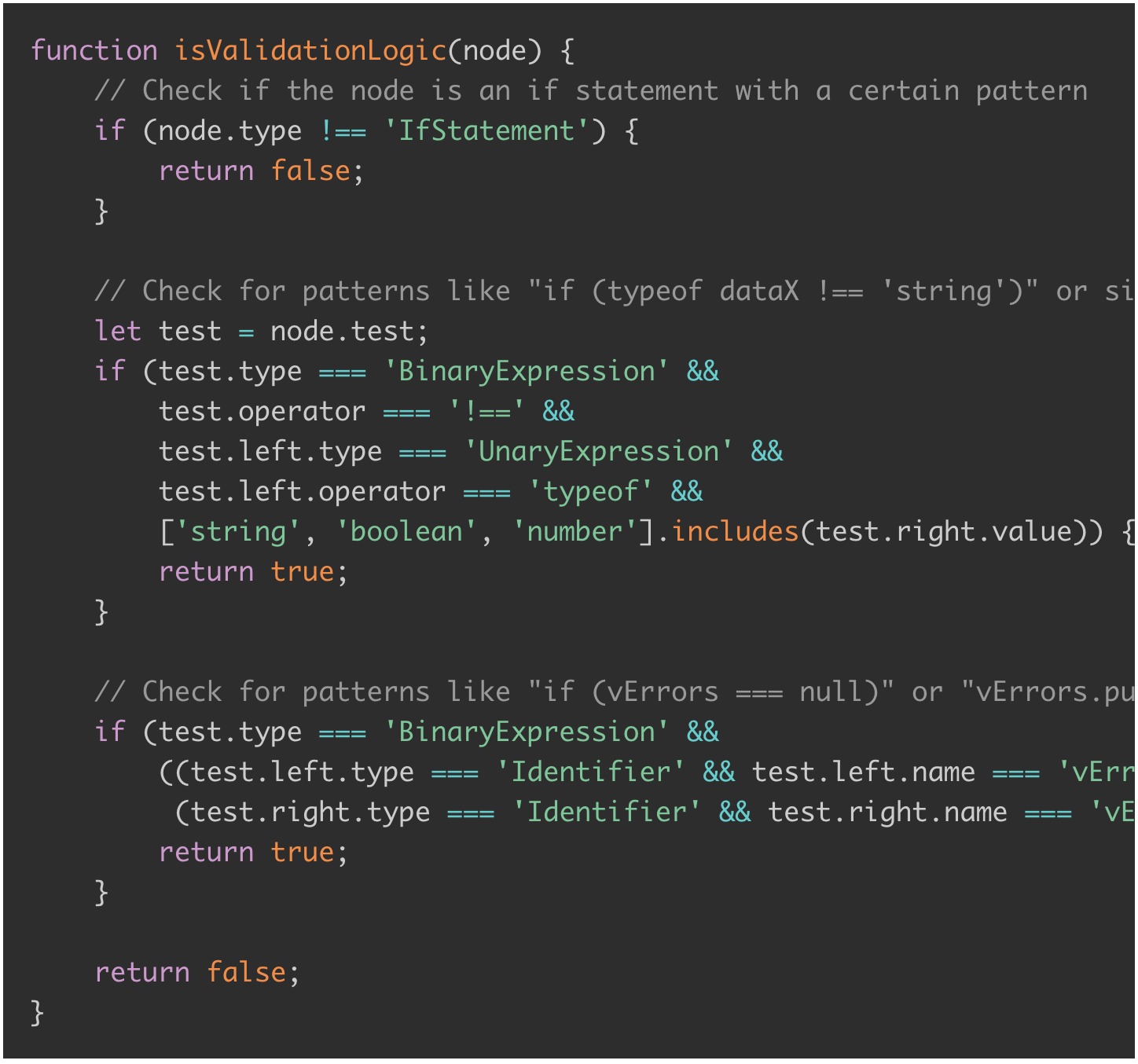
Various properties under the node object caught my attention; I realized that understanding these would be key. I asked again how my code, containing the blocks I wished to remove, would look after being processed by babel. As I followed the explanation, I also started to consult the babel official documentation to quickly elevate my understanding.
Despite my improved grasp, designing the logic to distinguish between code to delete and code to keep was still challenging, particularly due to two issues:
- Handling nested if statements without overly complicating the code.
- A validator function calls another validator, which calls another validator. I should only preserve the one with the real side effects.
At this point, I realized something crucial again. I was attempting to find a right answer right away. My approach needed a change in perspective.
4th Attempt: Hey ChatGPT, I Tried Refactoring Like This. I'm Having Trouble with This Part; What Would You Do Next?
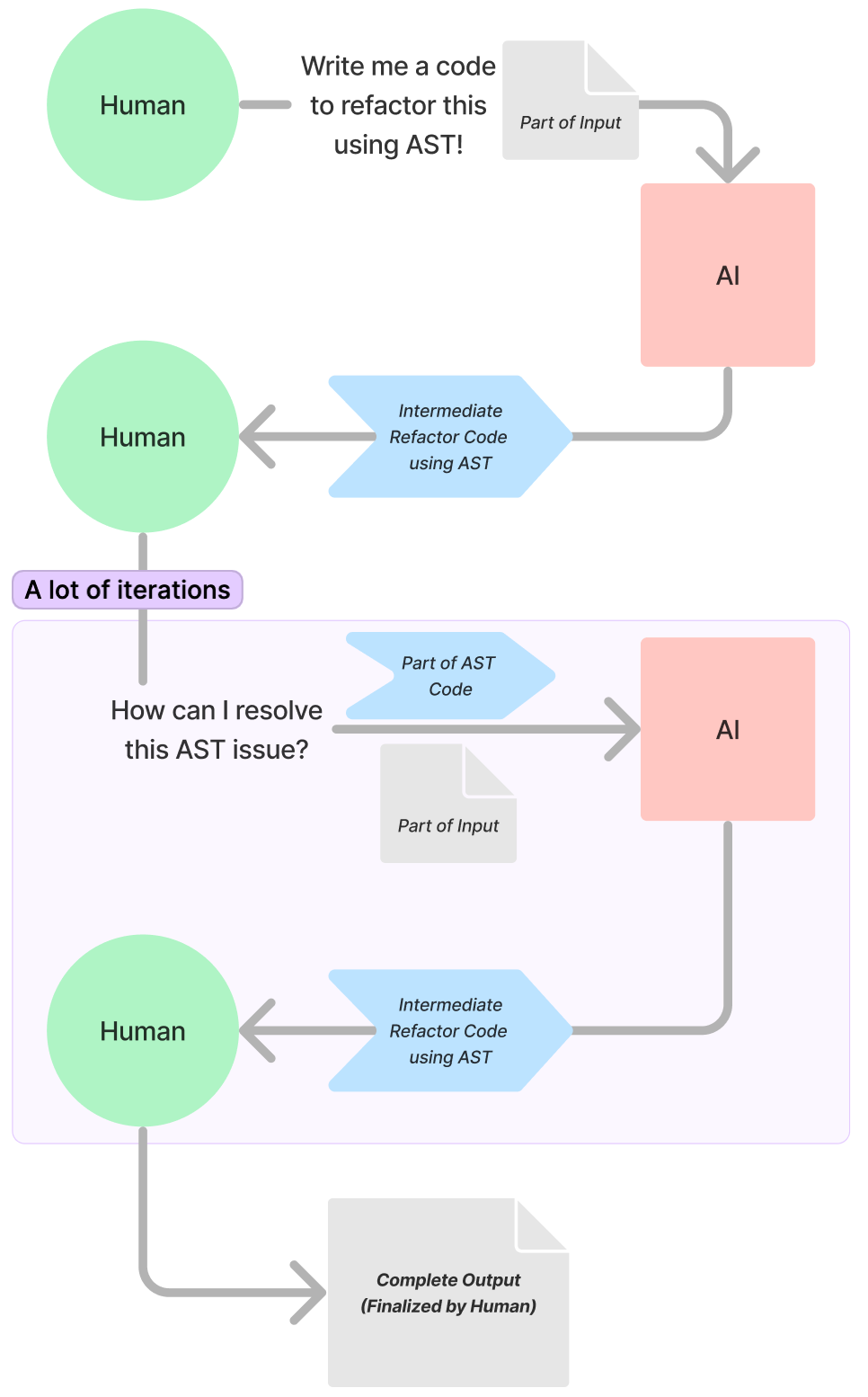
From this point, everything progressed smoothly. I executed a traversal with relatively simple logic, examined the output, and then approached ChatGPT with only the 'unfinished parts,' asking for advice on how to handle specific issues (e.g., how to preserve/delete this with babel). I iterated over this process, improving my babel code rapidly.
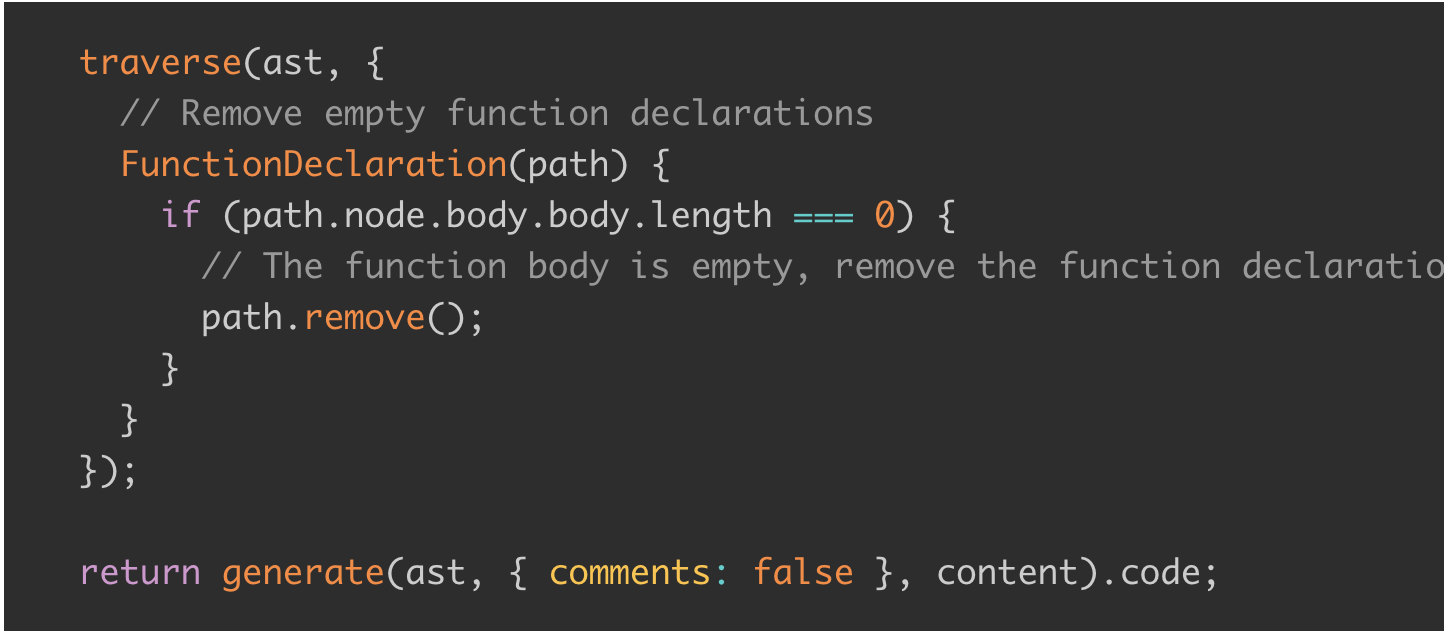
After removing sections of code, I ended up with many empty blocks like if(...) { }, for(...) { }. Removing these led to unused variables, and clearing those resulted in more empty blocks... Phew.
Fortunately, since I had already thought of "performing multiple traversals," the solution was straightforward: I simply ran it through multiple iterations, like this:

The code might have looked unsightly and inefficient, but what did it matter? It wasn't going to be part of the repository, and it was a script meant to be run just once. Initially, I had only performed clearEmpty and clearUnused once each, but as it wasn't clearing enough, I ended up adding more iterations until it reached this point.
At this juncture, I realized that although I initially intended to entrust ChatGPT with just one function, it seemed feasible to process the entire 18,500-line file with AST. The results were impressively handled. However, coding for scenarios where "a function calls another function" and deciding on changes remained challenging. So, after adding steps to remove empty functions at the end of the traverse and clear process:
I manually finalized the resulting code by visually inspecting it. After all, there wasn't much code left to go through.
Results
Completing this lengthy refactoring process in collaboration with ChatGPT left me incredibly proud. Specifically, I achieved the following results:
From the Product's Perspective
- file B was reduced from 18,500 lines to 1,335 lines.
- The main chunk bundle size decreased from 6.89MB to 6.35MB, a reduction of about 7.8%.
- The reduction in JS file size and logic required for initial loading led to a slight improvement in loading speed.
From My Perspective
- Gained experience and confidence in refactoring lengthy and complex legacy code using AST.
- Gained confidence that most complex problems can be effectively solved through three-way collaboration among AI + Code + Human.
This last point is the very reason I wrote this article.
Conclusion
While writing, I remembered a tweet I saw in January last year.
Santiago on X: "AI will not replace you. A person using AI will."
This could be true but we need to refine the meaning of ‘use’ here. Now I believe that if people merely 'use' AI, the change won't be significantly impactful. However, if the number of people who know how to collaborate effectively with AI continues to grow, many human labor tasks might be replaced. By ‘effective collaboration’, I mean the following :
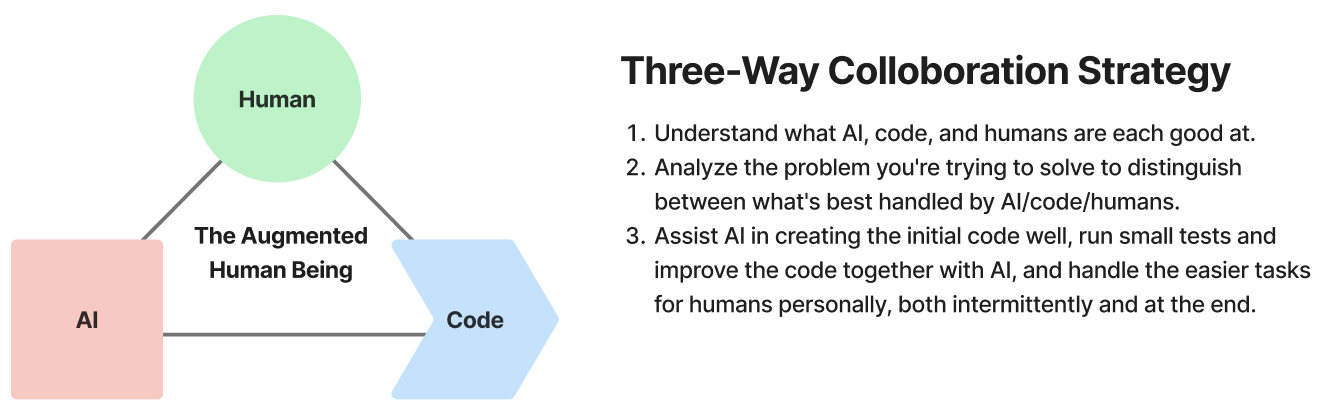
- Understand what AI, code, and humans are each good at.
- Analyze the problem you're trying to solve to distinguish between what's best handled by AI/code/humans.
- Assist AI in creating the initial code well, run small tests and improve the code together with AI, and handle the easier tasks for humans personally, both intermittently and at the end.
Through this process, I experienced a profound shift in how I view AI, making subsequent uses of ChatGPT significantly more beneficial. I think all good AI-based products will have some form of this, either explicitly or implicitly. This approach also mirrors what MediaCAT aims to achieve:
- AI: Machine-translate subtitles from one language to another.
- Code: Preprocess for easier AI understanding and operation, postprocess for easier human understanding and operation.
- Human: Final review and modification of machine-translated results, further facilitated by AI assistance.
For those who have been disappointed in the past by expecting 'right answers right away' from ChatGPT, I encourage you to try this tripartite collaboration model. I'm confident you'll experience a remarkable improvement in productivity.
Contributors
Ted Bae
Frontend Team Lead


